Современная сеть Internet это своеобразная паутина из паутин, собирающая в себе огромное число пользователей по всему миру. История его возникновения и развития это история глобальной кооперации и глобального сотрудничества. Сегодня к Интернету уже подключено более 750 миллионов компьютеров по всему миру. И это лишь та часть, которую мы можем увидеть в сети общего пользования. На самом деле, компьютеров еще больше многие из них прячутся за файрволами, а другие подключены лишь часть времени, то есть ноутбуки или домашние настольные компьютеры. Таким образом, 750 миллионов это лишь приблизительная оценка. На самом деле, количество пользователей в сети достигло уже почти двухмиллиардной отметки. Но есть одна цифра, которая не менее важна это количество мобильных устройств, вошедших в эту среду их почти 4,5 миллиарда. То есть мобильных устройств намного больше подключено, чем компьютеров. И это важно для развития Интернета, потому что многие из них имеют возможность полноценной работы в сети. Поэтому такие компании, как Google, которые предлагают людям услуги через Интернет, стремятся понять, каким образом предоставлять эти сервисы через мобильные телефоны там же маленький экран, маленькая клавиатура но при этом этот сервис должен быть таким, чтобы им можно было удобно пользоваться и при помощи мобильного устройства, и при помощи домашнего компьютера с большим экраном. И это достаточно большая проблема каким образом включить в пространство приложения пользователей мобильных телефонов, наравне с пользователями ноутбуков.
IP-протокол версии 6 (IPv6)
Как известно, подавляющая часть сети Internet базируется на IP-протоколе. Наиболее широко сейчас используется IPпротокол 4-й версии. Однако и он стал устаревать, но это означает рост глобальной сети и переход роли сети Internet на принципиально новый уровень. Осознание того, что IP-протокол устаревает, пришло еще в начале 90-х годов, и работы по созданию новой версии ведутся уже 10 лет. В его разработку, продвижение и внедрение вложено много сил и средств.
Основными причинами перехода к новой версии протокола являются необходимость расширения адресного пространства, растущая потребность поддержки мобильных систем, необходимость обеспечения нового уровня передачи информации и безопасности.
Первая причина самая очевидная. Сейчас адрес состоит из 32 бит. Это примерно 4 млрд. адресов. Несмотря на огромное количество «нулей», это адресное пространство весьма ограничено и уже сегодня довольно близко к своему наполнению. Новая же версия предлагает адрес из 128 бит, что обеспечит в общей сложности порядка 1039 млрд. адресов и, следовательно, значительно расширит возможности Глобальной сети.
Наблюдаемый сегодня активный рост сети Internet объясняется появлением все большего числа Internet-провайдеров, предоставляющих доступ в сеть. Кроме того, многие компании стремятся наделить свои изделия возможностью связи с глобальной сетью. В связи с этим возникает проблема: современная версия протокола не дает возможности быстрого подключения мобильных устройств. Сейчас имеется возможность динамического выделения адресов, но, попав в зону действия другого домена, необходимо изменять адрес, соответствующий устройству, так как в одном домене могут быть только устройства из этого домена. Повсеместно появляются новые технологии, использующие сеть Internet, например, электронная коммерция, передача радио и телевидения, IP-телефония и многое другое. Это, несомненно, связано с большим риском при передаче информации, и проблема безопасности, особенно в электронной коммерции, становится как никогда актуальной. Для решения этих и ряда других проблем и создается новая версия IP-протокола IP-протокол 6-й версии (IPv6).
Рассмотрим преимущества IPv6 подробней, проводя сравнение с 4-й версией.
- О количестве адресов было сказано выше.
- В новой версии существенно улучшены адресация и маршрутизация, что позволяет создавать изменяемую иерархическую структуру маршрутизации. В отличие от 4-й версии, в новом протоколе предусмотрена метка потока, которая содержится в заголовке пакета. Новый идентификатор потока может использоваться для более эффективной маршрутизации пакетов, даже когда информация и адрес зашифрованы. Более того, используя метки, можно различать пакеты, задавая различные правила их обработки маршрутизаторами. Также появились возможность автоконфигурации (усовершенствованный аналог динамического выделения адресов), то есть автоматического присвоения нового адреса или подключения имеющегося к новому маршрутизатору, создания специальных заголовков маршрутизации и новые средства безопасности специально для мобильных устройств. Это позволит облегчить работу с мобильными устройствами.
- В дополнение к имеющимся типам передачи данных «точка-точка» и «точкасеть», то есть все компьютеры этой сети (unicast и multicast), появилась возможность передачи данных одному из узлов сети (anycast). При этом способе информация передается на шлюз сети, но компьютер, распараллеливающий пакеты в сети, передает его не всем машинам, а лишь ближайшей или той, которая указана в настройках.
Заголовок IPv6 пакета упрощен, его длина фиксирована. Контроль передачи данных возложен на канальный уровень, и теперь в пакете нет контрольной суммы.
Как уже было отмечено выше, мало создать новый протокол его нужно внедрить. Хочется заметить, что созданием протоколов вообще и IPv6, в частности, занимается организация Internet Engineering Task Force (IETF). Именно она разрабатывает сам протокол, его спецификации, проводит тестирование и создает техническую документацию.
Производители операционных систем уже заявили и реализовали поддержку IPv6. В частности, такая поддержка есть в Linux и Windows. Разработчики сетевого оборудования, такие, как 3Com, Cisco и многие другие, включают в последние продукты поддержку новой версии, разработчики мобильных устройств работают над включением поддержки новой версии протокола в свои продукты.
Основной же проблемой, над которой необходимо серьезно работать, является сам процесс перехода. Дело в том, что нужен эффективный способ обеспечения совместимости 4-й и 6-й версий, вплоть до полного перехода на новую версию. Способов перехода, конечно, можно предложить много. Один из них туннелирование, идея которого состоит в том, что устанавливается поддержка нового протокола на компьютерах и маршрутизаторах, но 4-я версия оставляется. При этом 6-я версия как бы туннелирует под 4-й версией, то есть передается средствами 4-й версии вплоть до полного перехода всего данного сектора сети на IPv6. Здесь есть свои плюсы и минусы. Плюс в том, что имеется возможность плавного перехода без больших единовременных затрат денег и времени на тотальную замену всего. Минус в том, что требуется правильная и аккуратная настройка туннелей [2].
Таким образом, преимущества, которые дает IPv6, в сочетании с тенденцией наделить всех возможностью подключения к глобальной сети, новыми сервисами, обеспечивающими общение людей через сеть Internet и электронную коммерцию, указывают на необходимость самого скорейшего перехода на IPv6.
Семантическая паутина (Semantic Web)
Следующий шаг в будущее сети Internet разработка так называемой семантической паутины (Semantic Web), или, как ее еще называют, Web 3.0. Её идею в 2001 году опубликовал в журнале Scientific American изобретатель всей World Wide Web (Всемирной паутины) Тим Бернес-Ли [4].
Семантическая паутина (англ. Semantic Web) это направление развития Всемирной паутины, целью которого является представление информации в виде, пригодном для машинной обработки.
В обычной Паутине, основанной на HTML-страницах, информация заложена в тексте страниц и извлекается человеком с помощью браузера. Семантическая же паутина предполагает запись информации в виде семантической сети с помощью онтологий. Таким образом программа-клиент может непосредственно извлекать из паутины факты и делать из них логические заключения. Семантическая паутина работает параллельно с обычной Паутиной и на её основе, используя протокол HTTP и идентификаторы ресурсов URI.
При автоматической обработке информации в рамках Семантического Web взаимодействующие друг с другом сервисы на основе анализа смысловых связей между объектами и понятиями, хранящимися в Сети должны отбирать лишь ту информацию, которая будет реально полезна пользователям.
Промежуточной структурой между обычным интернетом и семантическим вебом являются банки данных, использующие семантические методы обработки информации. Главное их отличие от семантических поисковых систем и семантической паутины централизованность и вообще отсутствие какой-либо связанности с остальным интернетом. Примером проектов такого рода является известный многим Wolfram Alpha. Сервис умеет обрабатывать самые разные запросы например, выполнять любые вычисления с учетом размерности единиц, решать сложные уравнения, строить объемные графики, сравнивать несколько компаний на бирже, выводить указанные места генома человека, показать информацию об искусственном спутнике Земли и т.д.
Семантический Web можно представить как симбиоз двух направлений, первое из которых охватывает языки представления данных. На сегодняшний день основными такими языками являются Расширяемый Язык Разметки XML (eXtensible Markup Language) и Средства Описания Ресурсов RDF (Resource Description Framework). Существует также ряд других форматов, однако XML и RDF предоставляют больше возможностей, потому они обладают статусом рекомендаций W3C.
Второе, концептуальное направление несет в себе теоретическое представление о моделях предметных областей. Такие модели предметных обласей в терминологии Семантического Web называются онтологиями. 10 февраля 2004 года консорциумом W3C была утверждена и опубликована спецификация языка сетевых онтологий OWL (Web Ontology Language).
Таким образом, две ветви Семантического Web используют три ключевых языка (соответственно, технологий):
- спецификация XML, позволяющая определить синтаксис и структуру документов;
- механизм описания ресурсов RDF, обеспечивающий модель кодирования для значений, определенных в онтологии.
- язык онтологий OWL, позволяющий определять понятия и отношения между ними. Семантический Web использует также и другие языки, технологии и концепции, в частности, универсальные идентификаторы ресурсов, цифровые подписи, системы логического вывода и т.д.
Если говорить о логических уровнях, на которых базируется технология Семантического Web, то самый нижний уровень это Universal Resource Identifier (URI), унифицированный идентификатор, определяющий способ записи адреса произвольного ресурса. Семантический Web, именуя всякое понятие просто с помощью URIидентификатора, дает возможность каждому выражать те понятия, которыми он пользуется. Типичными примерами URIидентификаторов являются URL-адреса, однако URI-идентификатор, задавая или ссылаясь на некоторый ресурс, не обязательно при этом указывает на его местонахождение в Internet.
Следующий уровень язык XML как базовая форма разметки и средства, предназначенные для определения и описания классов XML-документов (DTD, XMLсхемы). Отдельный уровень в концепции Семантического Web ориентирован на работу с цифровой подписью, которая необходима, чтобы клиенты могли определять степень достоверности данных.
На базе XML кроме того развертываются средства описания ресурсов RDF и RDFсхемы, объясняющие, как состыковывать XML-данные в сети и строить каталоги и словари понятий. RDF позволяет выполнять поиск необходимых понятий в Семантическом Web.
И наконец, язык сетевых онтологий OWL предназначен для описания классов и отношений между ними, которые присущи как для сетевых документов, так и приложений. OWL обеспечивает более полную автоматическую обработку сетевого контента, чем та, которую поддерживают XML и RDF, предоставляя наряду с формальной семантикой дополнительную семантическую поддержку. При этом сами онтологии образуют систему, состоящую из наборов понятий и утверждений об этих понятиях, на основе которых можно строить классы, объекты и отношения. Отдельная онтология определяет семантику конкретной предметной области и способствует установлению связей между значениями ее элементов (рис. 1) [3].
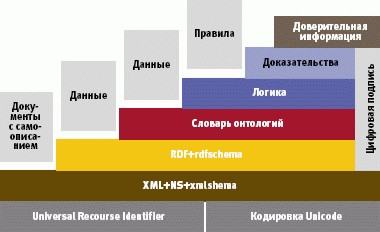
Рис. 1. Оригинальная модель Semantic Web (2001 г.)
Уже сегодня практически все известные компании уровня IBM, Adobe или Sun Microsystems активно используют технологию Семантического Web в своих продуктах для решения задач управления данными.
Компания Microsoft инвестирует сотни миллионов долларов в проект взаимодействующих сетевых ресурсов .NET, который отражает их представление о ближайшем будущем Internet. Создаваемая система позволяет проводить автоматизированный обмен сетевыми ресурсами между отдельными программами, приложениями, базами данных, пользователями, основываясь на XML как на ключевой технологии.
В Европе ведется проект, подобный Семантическому Web, "Сеть знаний", Knowledge Web (http://kw.dia.fi.upm.es/ semanticportal/ jsp/ frames.jsp). Эта сеть ориентирована на нужды информационных технологий в промышленности, науке и образовании, а Семантический Web (поддерживаемый и в Европе SWAD-Europe, www.w3.org/ 2001/ sw/ Europe/) больше рассчитан на электронную коммерцию и упрощение работы пользователей сети Интернет.
Недавно в рамках идеологии Семантического Web была разработана в School of Electronics & Computer Science (ECS) Университета Саутгемптона система mSpace. Программное обеспечение данной системы представляет собой набор мощных инструментов, позволяющих собирать данные из различных источников и организовывать информацию по категориям и дающих возможность пользователю свободно ориентироваться в ней.
Разработчики приводят следующий пример. Например, если в Google набрать "классическая музыка", то поисковик выдаст ссылки на сайты, так или иначе касающиеся классической музыки. Если же искать "классическую музыку" на mSpace, то будет выдан список композиций, которые можно тут же скачать. Другой пример по запросу "Гарри Поттер" пользователь получит не просто набор ссылок, а отсортированный отчет, в котором часть ссылок будет лежать в графе "фильмы", другая часть в колонке "книги", а третья в колонке "рецензии". Семантический Web предоставит пользователю возможность выбирать, в каком направлении исследовать информацию, а не просто выдавать самое релевантное по общему алгоритму.
Если говорить о перспективах, то, благодаря Семантическому Web, Internet сможет выйти из намечающегося кризиса, связанного с «проблемой размерности». Появилась надежда, что компьютеры смогут обрабатывать данные в соответствии с их смыслом, следуя по гиперссылкам, ведущим к определениям ключевых терминов и правилам логических выводов. Полученная в результате инфраструктура даст отправную точку для разработки автоматизированных Web-сервисов, интеллектуальных агентов, ведь сама идея Семантического Web основана на стремлении «научить» компьютерные программы, Web-службы и роботы поисковых систем и агентов «осмысленно» оперировать той информацией, для которой последние были созданы.
Семантический Web обещает вполне ощутимые преимущества, дополнительные сервисы. Навигация в Сети станет более осмысленной, а поиск более точным. Сами пользователи смогут создавать страницы Семантического Web, давать собственные определения и вводить новые правила вывода, используя стандартное для этой сети программное обеспечение.
Семантический Web это не какая-то отдельная сеть, а расширение и эволюция уже существующей, но при этом информация снабжена точно определенным смыслом, позволяющим человеку и программам успешно взаимодействовать. Сегодня происходит активная интеграция новых элементов Семантической Сети в структуру традиционного Web. Семантический Web уже вполне готов к широкому внедрению в корпоративном секторе, он перерос границы чисто исследовательского проекта, все его основополагающие технологии становятся стандартами, а крупные участники рынка высоких технологий внедряют их в прикладные программы корпоративного уровня.
В настоящее время на Семантический Web работает множество научных подразделений по всему миру, совершенствуя и разрабатывая новые протоколы, технологии, среды программирования, агенты, языки, пользовательские интерфейсы, методы распределенного поиска знаний. Прогнозируется, что работоспособная глобальная версия Семантической сети появится уже в этом десятилетии. О реальности этого прогноза свидетельствует публикация и утверждение WWW-консорциумом в феврале 2004 года финальных версий двух основных спецификаций Семантического Web. Это пересмотренная версия RDF (в нее добавлены описания тестов, позволяющие приложениям на разных языках программирования понимать друг друга, а также средства стыковки RDF и XML) и OWL.
ЛИТЕРАТУРА
- Андреев А.М., Березкин Д.В., Симаков К. В. Особенности проектирования модели и онтологии предметной области для поиска противоречий в правовых электронных библиотеках. 6-ая Всероссийская научная конференция RCDL' 2004.
- Кошелев А.В. IPv6 новый двигатель для Интернета. КомпьютерПресс 10. 2000.
- Ландэ Д.В. Поиск знаний в Internet. Профессиональная работа. М.: Диалектика, 2005. 272 c.
- Материалы сайта Wikipedia. Semantic Web