Аннотация
В данной статье рассматриваются перспективные методы и вычислительные платформы для проведения экономических расчетов, а также кратко рассматриваются конкретные вычислительные платформы применительно к экономическим расчетам и дальнейшие тренды их развития. Данная статья так же рассматривает проблему обработки объемов больших данных в экономике и рассматривает возможные пути решения. Статья так же будет полезна всем, кто имеет дело с экономическими расчетами больших объемов, в качестве обзорной.
В настоящее время проявляется активная тенденция использования современных вычислительных платформ в экономических расчетах. Мощности современных вычислительных машин растут согласно закону Mypa и удваиваются каждые 24 месяца соответственно, растет скорость, точность и масштабы расчетов. На сегодняшний день, самые популярные технологии, используемые в области вычислений и работы с большими объемами данных, являются Datamining и DeepLearning, это два основных раздела целой новой науки BigData каждый из которых имеет свои подразделы (Рисунок 1) и мульти дисциплинарные связи. BigData является в свою очередь парадигмой, которая объединяет в себе огромное число алгоритмов, схем, математических моделей и даже теорию машинного обучения для формирования целостной системы обработки гигантских объемов данных. Если рассматривать эволюцию вычислительных платформ используемых с самых древних времен, то можно заметить какой колосальный скачок был сделан за относительно короткое время. Был проделан путь от простых счетов типа Аббак до современной микропроцессорной многоядерной вычислительной мощи. Однако же стоит отметить, что мало использовать мощные машины, очень важно то как их использовать и какие применять алгоритмы. Древние счеты позволяли использовать несколько простых примитивных алгоритмов, в то время как в настоящее время обилие различных алгоритмов породило целые вычислительные платформы сопреничающие друг с другом.
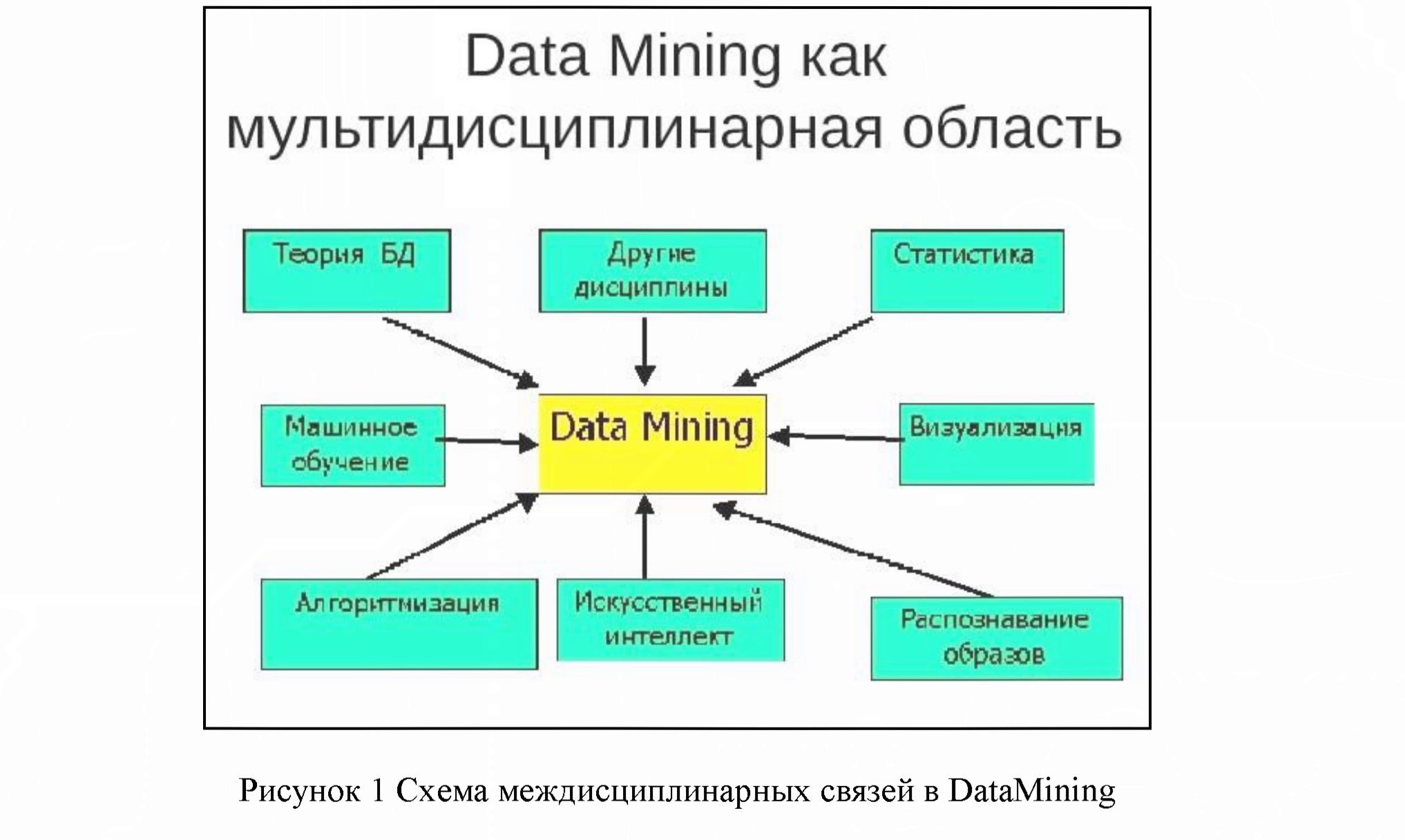 Современный термин DataMining переводится как «извлечение информации» или «добыча данных». Довольно часто, наряду с DataMining встречаются термины KnowledgeDiscovery («обнаружение знаний») и DataWarehouse («хранилище данных»). Возникновение указанных терминов, которые являются неотъемлемой составляющей частью DataMining, связано с новым витком в развитии средств и методов обработки и хранения данных. Итак, цель DataMining состоит в выявлении скрытых правил и закономерностей в больших (очень больших) объемах данных, которые в экономических расчетах имеют довольно важное значение, в частности при прогнозировании различных значений, таких как, например курсы валют или другой статистической информации, для построения линий трендов и так далее [3].
Современный термин DataMining переводится как «извлечение информации» или «добыча данных». Довольно часто, наряду с DataMining встречаются термины KnowledgeDiscovery («обнаружение знаний») и DataWarehouse («хранилище данных»). Возникновение указанных терминов, которые являются неотъемлемой составляющей частью DataMining, связано с новым витком в развитии средств и методов обработки и хранения данных. Итак, цель DataMining состоит в выявлении скрытых правил и закономерностей в больших (очень больших) объемах данных, которые в экономических расчетах имеют довольно важное значение, в частности при прогнозировании различных значений, таких как, например курсы валют или другой статистической информации, для построения линий трендов и так далее [3].
Сложность экономических расчетов, да и любых других, где используется большое число данных, состоит в том, что человеческий разум сам по себе не приспособлен для восприятия огромных массивов разнородной информации.
В среднем человек, за исключением некоторых индивидуумов, не способен улавливать более двух-трех взаимосвязей даже в небольших выборках. Но и традиционная статистика, долгое время претендовавшая на роль основного инструмента анализа данных, так, же нередко пасует при решении задач из реальной жизни. Она оперирует усредненными характеристиками выборки, которые часто являются фиктивными величинами (средней платежеспособностью клиента, когда в зависимости от функции риска или функции потерь вам необходимо уметь прогнозировать состоятельность и намерения клиента; средней интенсивностью сигнала, тогда как вам интересны характерные особенности и предпосылки пиков сигнала и т. д.) [4].
Таким образом, стоит сделать вывод о том что, дальнейшее совершенствование и развитие вычислительных платформ для обработки большого объема данных (а именно в области экономики зачастую объемы входных данных самые большие) имеет далеко идущие перспективы, а так же востребованность. Итак, рассмотрим следующий подход к обработке данных в экономике.
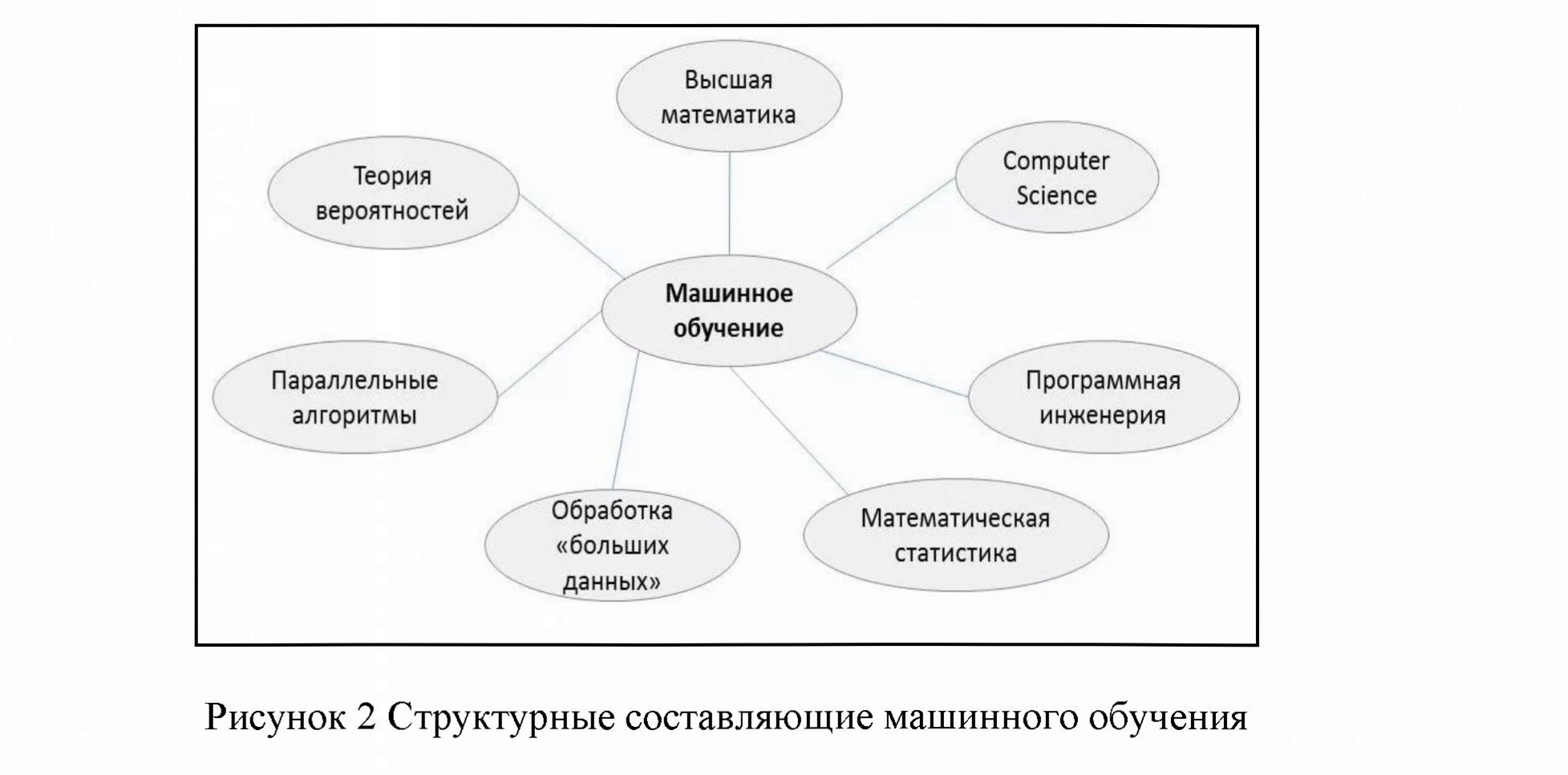
Машинное обучение (от англ. - machinelearning) - алгоритмы, или же набор алгоритмов, позволяющие компьютеру делать выводы на основании данных, не следуя определенным правилам (Рисунок 2).
Принято выделять 2 направления:
1. Обучение на основе выявления закономерностей в данных.
2. Обучение, основанное на формализации знаний экспертов и их перенос в виде базы знаний.
Целью машинного обучения является разработка алгоритмов с возможностью воспроизведения работы человеческого мозга при анализе информации и в ходе принятия решения [5].
Таким образом выполнять экономические прогнозы и расчеты, платформа учится самостоятельно, основываясь на выявлении закономерности во входных данных, такой подход практически не требует участия человека.
Текущая стадия развития обучающихся алгоритмов такова, что под термином «обучение» понимается способность решать уравнения на основе определенных данных, например, данных о курсах валют за последние 10 лет, расчеты будут тем точнее, чем больше входная выборка данных.
Сфера применений машинного обучения постоянно расширяется. Повсеместная информатизация приводит к накоплению огромных объёмов данных в науке, производстве, бизнесе, транспорте, здравоохранении.
Возникающие при этом задачи прогнозирования, управления и принятия решений часто сводятся к обучению по прецедентам. Раньше, когда таких данных не было, эти задачи либо вообще не ставились, либо решались совершенно другими методами.
Машинное обучение и элементы искусственного интеллекта, настоящий спасательный круг в экономических расчетах, так как в этой области объемы и выборки входных данных постоянно увеличиваются. Машинное обучение может в корне изменить и упростить процесс проведения расчетно-вычислительных процессов в экономике.
На данный момент машинное обучение и DataMining являются довольно распространенными подходами к решению подавляюще большого числа задач из области экономики. Однако, же если для использования Data Mining существует внушительный набор платформ, таких как:
- MatLab;
- Mathcad;
- Maple;
- SPSS;
- Statistika.
Для использования подхода в машинном обучении, не существует пока стандартизированной платформы, однако с появлением языка программитрования Python появился новый гибкий инструмент для выполнения расчетов почсредством машинного обучения.
Код на python может быть помещен в файл с расширением .ру и отправлен интерпретатору для выполнения, то классический подход, который обычно разбавляется использованием среды разработки, например pyCharm [2]. Однако, для python (и не только) существует другой способ взаимодействия с интерпретатором — интерактивные блокноты jupyter (Рисунок 3), сохраняющие промежуточное состояние программы между выполнением различных блоков кода, которые могут быть выполнены в произвольном порядке.
Экосистема языка Python стремительно развивается[1]. Это уже не просто язык общего назначения. C его помощью можно успешно разрабатывать вебприложения, системные утилиты и многое другое. Рассмотрим сильные и слабые стороны идеи использования python вместо MATLAB, Maple, Mathcad, Mathematica.
Этот способ взаимодействия позаимствован у блокнотов Mathematica, позже аналог появился и в MATLAB (Live script). Таким образом, Руйюпстановится на настоящий момент самой перспективной вычислительной платформой использующей подход машинного обучения.
В настоящее время для данного языка разработано и находится в процессе разработки огромное число вычислительных библиотек, позволяющие реализовывать с помощью него практически сколь угодное число различных вычислений. Развитие данной платформы, на настоящий момент идет очень быстрыми темпами, и именно данная платформа претендует на роль основной вычислительной платформы для расчетов в области экономики в ближайшем будущем.
Литература
- Доусон М. Программируем на Python. - СПб.: Питер, 2016. - 416 с.
- Лутц М. Изучаем Python, 4-е издание. - Пер. с англ. - СПб.: Символ-Плюс. 2015. - 1280 с.
- Bigus. J.P. Data mining with neural networks / Bigus J.P.. - M.: [не указано]. 2015. - 835 с.
- Boris, Kovalerchuk Data Mining in Finance: Advances in Relational and Hybrid Methods (Kluwer International Series in Engineering and Computer Science. 547) / Boris Kovalerchuk. Evgenii Vityaev. - Москва: СПб. [и др.] : Питер, 2016. - 209 с.
- Флах. Петер Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных. Учебник / Петер Флах. - M.: ДМК Пресс. 2015. - 400 с.