In this research study the effect of normalization techniques is examined. The five different supervised machine learning algorithms i.e., KNN, Decision tree, Naïve-base, Logistic regression and ANN are used on breast cancer dataset obtained from UCI machine learning repository and their performances are compared. The study reveal that different preprocessing techniques can increase the classification accuracy over 90% where high performance is given to Logistic regression and ANN. The proposed approach can be implemented in a well-known benchmark medical problem with real clinical data forbreast cancer disease diagnosis.
breast cancer plays an important role. Breast cancer is the most common cancer among women, except for skin cancers. According to CDC statistics 1 in 8 (12%) women in the US will develop invasive breast cancer during their lifetime. Breast cancer starts when cells in the breast begin to grow out of control [8]. These cells usually form a tumor that can often be seen on an x-ray or felt as a lump. The tumor is malignant (cancerous) if the cells can grow into (invade) surrounding tissues or spread (metastasize) to distant areas of the body. Breast cancer occurs almost entirely in women, but also possible to occur in men.It's also important to understand that most breast lumps are not cancer, they are benign. Benign breast tumors are abnormal growths, but they do not spread outside of the breast and they are not life threatening. But some benign breast lumps can increase a woman's risk of getting breast cancer. Any breast lump or change needs to be checked by a health care provider to determine whether it is benign or cancer, and whether it might impact your future cancer risk [4].
The goal of a study is to reveal the presence of tumor and classify into two classes benign or malignant.During the analysis we studied the effect of preprocessing and normalization techniques on classification model. The published literature suggests that machine learning (ML) algorithms have been shown to be valuable tools in reducing the workload on the clinicians by detecting artefact and providing decision support, potentially with the ability to automatically re-estimate the prediction or classification model in real-time.
- materials and methods.
2.1 Machine Learning Algorithms.
The scikit-learn machine learning framework with five algorithms has been used to evaluate the classification performance on breast cancer dataset. The brief explanations for algorithms are provided below.
- K Nearest Neighbors (KNN) algorithm is one of the first simple supervised learning machine learning algorithms. The logic behind this method is to find a predefined number of training samples closest in distance to the new point, and predict the label from these given data-points. Despite its simplicity, nearest neighbors has been successful in a large number of classification and regression problems. As a distance metric generally the Euclidean distance measure is used. For detailed information refer [1].
- Decision Trees (D-Tree)is a supervised learning method that is used for classification and regression. The feature is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features. This method has some advantages like being simple to understand and easy to interpret and also trees can be visualized and requires little data preparation. The method is based on information theory paradigm. The more information can be obtained [1].
- Gaussian Naïve Bayes (NB) is a classification technique based on Bayes' Theorem. In general, the Naïve Bayes classifier assumes the presence of a particular feature in a class is unrelated to the presence of any other feature. For example, a fruit may be considered to be an orange if it is orange, round, and about 10 cm in diameter. Even if these features depend on each other or upon the existence of the other features, all of these properties independently contribute to the probability that this fruit is an apple and that is why it is known as ,Naive'. This method's advantage is that Naive Bayes model is easy to build and particularly useful for very large data sets. For details refer [1].
- Logistic regression (Logit)is a part of regression models where the output value is binary or dichotomous. The prediction curve is S-shaped and based on a sigmoid function [1]. Because of non-linear nature this algorithm shows one of the best results on getting the classification model for the data, for details refer results and discussion section.
- Artificial Neural Network (ANN)is a new alternative to Logit, the statistical technique with which they share the most similarities.Neural networks are algorithms that are patterned after the structure of the human brain [1]. They contain a series of mathematical equations that are used to simulate the biological processes such as learning and memory.In a ANNs, one has the same goal as in Logit modeling, predicting an outcome based on the values of some predictor variables.
2.2. Data collections.
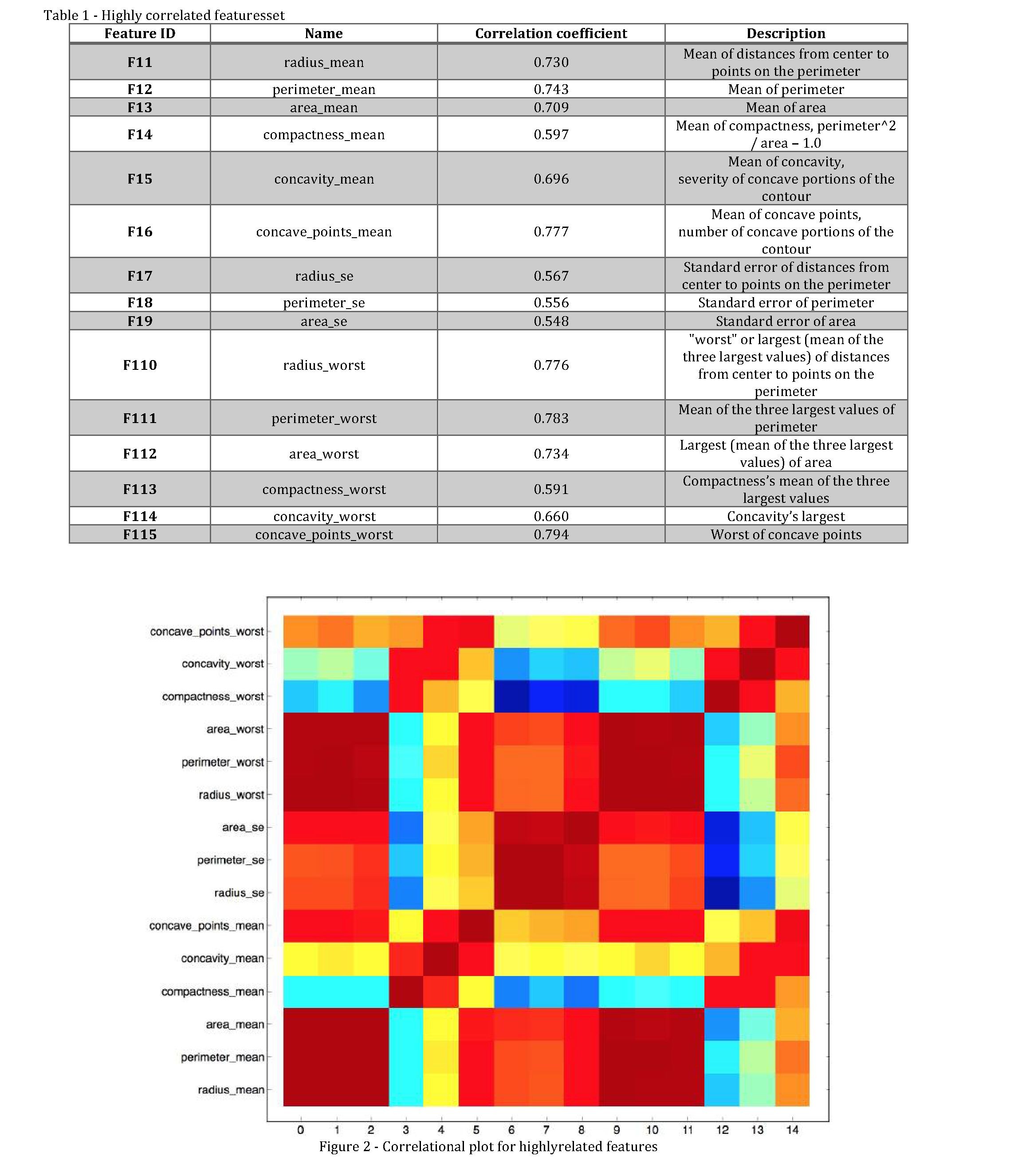
The dataset obtained from UCI machine learning repository. There are 31features and over 600 instances.Table 1 shows details of attributes with correlation coefficients. The target attribute provides 4 categories where first three are related to heart diseases and last one to healthy state. The hold-out method used for training and testing the models, where 70% for training set and 30% for testing set.
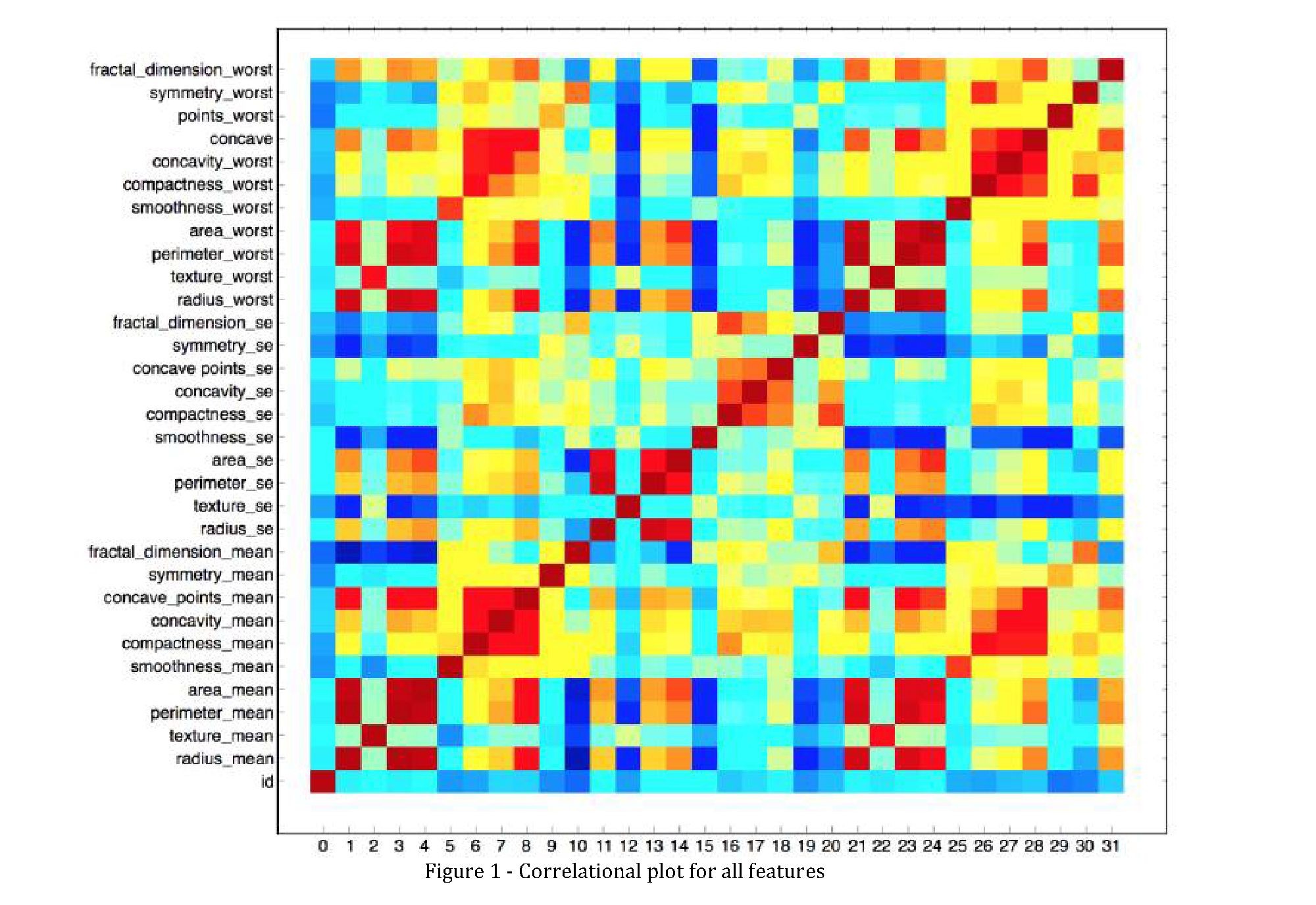
In the Figure 1, we can see a correlational plot for 31 features. The red square cells indicate the high correlation whereas the blue dots low correlation. The dataset has been divided into two parts with highly correlated features and low ones. The goal was to study the effect of correlation and preprocessing techniques on classification performance of algorithms. The correlation was found by using spearman method, because it will be more precise for non-linear dataset. The features in highly correlated dataset is between ±0.5≤r≤±1 whereas in low correlated is -0.49≤r≤+0.49.

This section reviews several studies related to applications of machine learning algorithms for working with medical data especially related to cancer. It can be seen that a great variety of methods were used which reached high prediction and classification accuracies using the datasets generally taken from UCI-ML repositories.Zhongyu Pang and Lloyd, S.R (2008) developed an innovative signal classificatio n method that is capable of differentiating subjects with sleep disorders which cause excessive daytime sleepiness (EDS) from normal control subjects who do not have a sleep disorder based on EEG and pupil size [2]. In another study, Kiyan et. al., trained Neural Network using back propagation and achieved an accuracy level on the test data of approximately 94% on breast cancer data [3]. The authors in this research study [4] presented BP-ANN attempt where they used 47 input features and achieved an accuracy of 95%.Moris et al. used logistic regression algorithm on heart diseases dataset. By applying various preprocessing techniques, he achieved in obtaining 77.0% of classification accuracy [5]. Further, Kamruzzaman et al. proposed a neural network ensemble based methodology for diagnosing of the heart disease diagnosis and achieved prediction accuracy over 80% [6]. Moreover, Das et al.[7] in 2008 applied genetic algorithm (GA) based Neuro Fuzzy Techniques for breast cancer identification and adaptive neuro fuzzy classifier has been introduced to classify the tumor mass in breast. So from the research studies above it can be seen the ml algorithms can be successfully applied in medical field.
Models simulations performed over scikit-learn ml framework for 5 different algorithms explained in Section 2.1 over breast cancer dataset. In order to reveal the true potential of algorithms the dataset has been divided into two parts shown in Table 1 and 2. The first part contains the highly correlated features where r >= 0.5 and second part is lower than r < 0.5.
The accuracy scores before preprocessing are given in Figure 6. We can see that Logit and DT are performing the best. The
standardization preprocessing technique gave the highest accuracy scores for ml algorithms.
After applying the normalization technique, we can see that there is an effect on accuracy scores. In this case KNN and DT shows
the highest scores for over 90% but the accuracy scores for other drops shown in Figure 7.
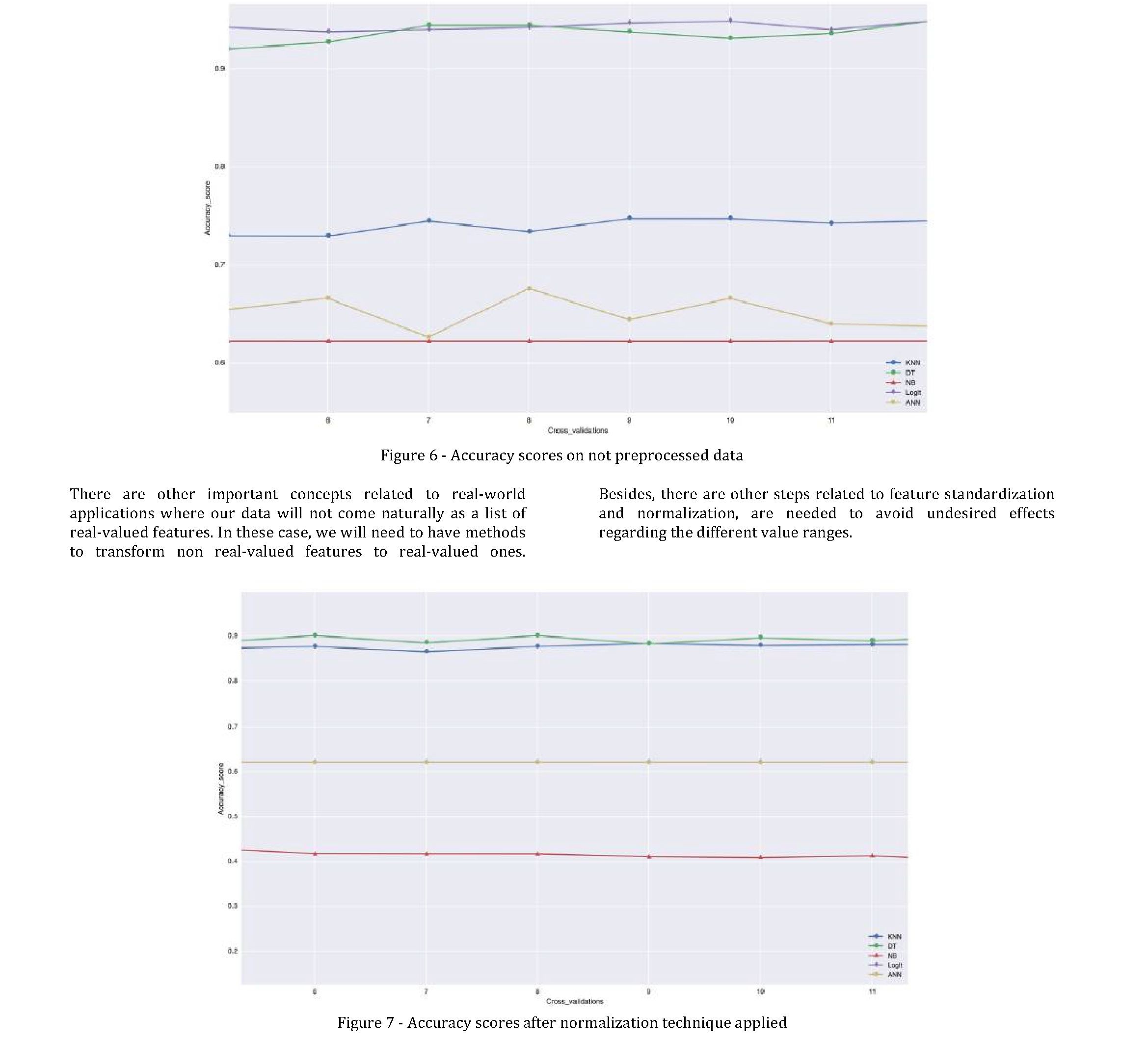
The standardization technique best fits the Logit and ANN algorithms; we can see that the accuracy scores for them increases over 92% shown in Figure 8. So there is an effect of correlation and normalization techniques on accuracy scores. Conclusions.
The breast cancer is one of the most common and deadly diseases in the world. The detection and diagnosis of breast cancer in its early stage is the key of its cure for women. In this research study we have analyzed the effect of different preprocessing techniques on ml algorithms accuracy scores. The study found that normalization increases scores for KNN and DT for over 90% but the accuracy scores for other drops. On the other hand, the standardization increases the scores for the Logit and ANN algorithms for over 92%. In conclusion we can say that before making any diagnostic assumptions several preprocessing techniques has to be applied and accuracy scores tested.
REFERENCES
- Harrington, Peter. “Machine learning in action”. - Greenwich, CT: Manning, 2012. - Vol. 5. - Р. 88-96.
- Derong Liu; Zhongyu Pang; Lloyd S.R, “A Neural Network Method for Detection of Obstructive Sleep Apnea and Narcolepsy” // Based on Pupil Sizeand EEG. - 2008. - V.19, I.2. - Р. 126-169.
- Kiyan, T., and Yildirim, T. (2003). Breast Cancer Diagnosis Using Statistical Neural Networks // International XII. Turkish Symposium on Artificial Intelligence and Neural Networks. University Besiktas, Istanbul. - Turkey: 2003. - Р. 51-56.
- Seker .H., Odetao M.,Petroric D. and Naguib R.N.G.(1994)- “A fuzzy logic based method for prognostic decision making in breast and prostrate cancers” // Biomedicine (IEEE transactions). - 2003. - №73. - Р. 88-96.
- S. Haykin. Neural Networks: A Comprehensive Foundation. - New York: 1994. - 523 р.
- Morise, A. P., Detrano, R., Bobbio, M., & Diamond, G. A. (1992). Development and validation of a logistic regression-derived algorithm for estimating the incremental probability of coronary artery disease before and after exercise testing // Journal of the American College of Cardiology. - 1992. - №20(5). - Р. 1187-1196.
- S. M. Kamruzzaman, Ahmed Ryadh Hasan, Abu Bakar Siddiquee and Md. EhsanulHoqueMazumder // Medical diagnosis using neural network, ICECE 2004, 28-30 December 2004. - Dhaka, Bangladesh: 2004. - Р. 28-34.
- Arpita Das and Mahua Bhattacharya, GA based Neuro Fuzzy Techniques for breast cancer Identification // IEEE. - 2008. - №2. - Р. 978986
- Hongmin Zhang, Xuefeng Dai, The Application of Fuzzy Neural Network in Medicine-A Survey // International Conference on Biological and Biomedical Sciences Advances in Biomedical Engineering. - 2012. - Vol.9. - Р. 52-56.