В статье разработан комплекс элементов теории классификации на примере алгоритма прямой классификации упрощенным методом K – ближайших соседей; интерпретации полученных результатов эмпирической статистической обработки данных.
Введение Всё множество задач элементов статистической обработки данных сводится к задачам описания и прогноза. На начальном этапе статистического исследования ставится цель определения объекта и его описания. В том случае, если объектом исследования является выборка, то методами разведочного (предмодельного) статистического анализа данных необходимо определить вероятностную и геометрическую природу обрабатываемых данных, а также выяснить, однородны ли имеющиеся эмпирические данные, т.е. целесообразно ли разбиение совокупности на части, представляющие собой кластеры. В последствии на основе этих заключений формируются адекватные реальности рабочие допущения, на основе которых осуществляется дальнейшее исследование.
Поэтому стала актуальной проблема разработки средств автоматизации, позволяющих построить статистическую модель в виде эмпирического описания структуры данных, которую необходимо в ходе статистического исследования верифицировать.
Если объектом исследования является выборка, которая принадлежит к нормальному распределению, то задача статистической обработки сводится к оценке её параметров. Для оценки параметров выборки можно воспользоваться методом нормальной вероятностной бумаги. В том же случае, когда конкретный вид функции распределения неизвестен, и о виде распределения можно сделать лишь самые общие предположения, то при таких условиях можно воспользоваться аппроксимациями неизвестной функции распределения на основе выборки (x 1, x 2 ,..., x N ) , называемыми непараметрическими, а именно - гистограммой и полигоном частотдля статистических данных с разбиением на интервалы равной длины, или с разбиением на равнонаполненные интервалы, непараметрической оценкой функции плотности распределения вероятности для статистических данных методом прямоугольных вкладов.
Эти методы предусматривают однообразные и рутинные вычисления, поэтому стала актуальной разработка средств автоматизации проверки правильности производимых расчётов.
Работа посвящена созданию обучающих средств, помогающих студентам в изучении и освоении метода оценки параметров выборки с помощью нормальной вероятностной бумаги, непараметрических методов аппроксимации функции распределения и метода классификации экспериментальных данных упрощенным алгоритмом K – ближайших соседей.
В качестве среды реализации алгоритма был выбран встроенный пакет анализа данных EXCEL, потому что он является базовым компонентом MicrosoftOffice и доступен большинству обычных пользователей.
Первичные данные, полученные при наблюдении, обычно трудно обозримы. Для того чтобы начать анализ, в них надо внести некоторый порядок и придать им удобный для исследователя вид. В частности, для начала желательно получить представление об одномерных распределениях случайных величин, входящих в данные.
Существуют два типа задач аппроксимации распределений [2,4]. Если вид функции распределения известен, но не известны ее параметры, тогда задача сводится к параметрическому оцениванию. Бывают ситуации, когда конкретный вид функции распределения неизвестен, и о виде распределения можно сделать лишь самые общие предположения. При таких условиях аппроксимацию неизвестной функции распределения
на основе выборки (x 1, x 2 ,..., x N )называют непараметрической.
Средства автоматизации алгоритма прямой классификации
Разработанные средства автоматизации алгоритма прямой классификации предназначены для использования в процессе изучения студентами азов теории классификации. Они ориентированы на выработку у студентов интуиции о влиянии характера исходных данных, а также способов измерения близости между объектами и типе нормировки на результат классификации.
Диалог с пользователем осуществляется при помощи пользовательской формы. При нажатии на соответствующие кнопки формы, происходит выполнение необходимых вычислений. Действия, которые производят разработанные макросы для кнопок, разбиты на 5 этапов.
Этап 1. Генерация выборки. Для изучения влияния характера исходных данных на результат классификации используется генерация псевдослучайных величин средствами EXCEL.
С помощью генератора случайных чисел можно построить последовательности с нормальным распределением. Очень многие модели, построенные с помощью этого распределения, хорошо соответствуют действительности. Чтобы построить последовательность значений нормально распределенной случайной величины, необходимо задать математическое ожидание и дисперсию.
Чтобы сгенерировать последовательность, необходимо воспользоваться функцией из встроенного пакета анализа данных:
- Выбрать команду Сервис, Анализ данных (Tools, DataAnalysis). Появляется диалоговое окно Анализ данных
- Выбрать пункт Генерация случайных чисел (Random Number Generation).
Появляется диалоговое окно Генерация случайных чисел.
- Выбрать Нормальное распределение в списке Распредеение (Distribution).
- Ввести число 3 в поле Число переменных (Number of Variables), что означает число столбцов, которые заполнены последовательностью.
- Ввести число 20 в поле Число случайных чисел (Number Random Numbers), т. е. последовательность занимает 20 строк.
- Нажать кнопку ОК. Если указанный на рабочем листе диапазон содержит другие данные, появится окно сообщения, где необходимо будет подтвердить замену данных.
EXCEL создаст последовательность.
Первая половина выборки в разработанном макросе сгенерирована случайным образом из нормального распределения с параметрами математическое ожидание 0 и дисперсия 1 (μ = 0, σ = 1).
Вторая половина выборки сгенерирована случайным образом из нормального распределения с параметрами математическое ожидание 2 и дисперсия 1 (μ = 2, σ = 1).
Замечание. Для изменения исходных параметров в теле макроса делаются корректировки. Например, для математического ожидания со значением 0 дисперсии со значением 1 данный фрагмент реализации в макросе выглядит следующим образом:
For i = 1 To m Randomize
Cells(i + 1, 1) = RndN(0, 1) Next i
For i = 1 To m Randomize
Cells(i + 1, 2) = RndN(0, 1) Next i
For i = 1 To m Randomize
Cells(i + 1, 3) = RndN(0, 1) Next i
Этап 2. Рабочие расчеты. Для классификации необходимо провести дополнительные рабочие расчеты, как-то: вычисление максимальных и средних элементов выборки, нормировка выборки.
Первоначально каждый объект заданной совокупности описан тремя признаками по двадцать элементов каждый.
Для каждых членов исходных рядов в ячейки D4, E4, F4 заносятся значения, соответствующие средним значениям.
Для каждых членов исходных рядов в ячейки D7, E7, F7 заносятся значения, соответствующие максимальным значениям.
В процессе исследования в качестве нормировок были выбраны две.
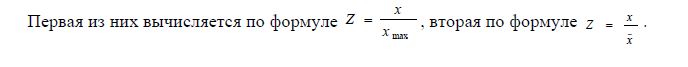
Этап 3 Расчет матриц расстояний. В качестве определения расстояния между объектами выбраны линейное и евклидово расстояния.
Этап 4 Выделение 2 классов, вывод промежуточных результатов. На этом этапе производится выделение двух классов для построенных на первом этапе исходных данных. Начальное разбиение выборки задается двумя способами. Первый способ заключается в том, что первая половина элементов выборки принимается за первый класс, а вторая – за второй. Второй способ разбиения заключается в том, что в первый класс будут входить нечетные элементы выборки, а во второй - четные. На рабочем листе при помощи макроса реализованы следующие действия: отображено первоначальное разбиение выборки на 2 класса, промежуточные результаты по работе макроса, будет отображение конечного результата разбиения выборки на два класса. По полученным разбиениям
построены графики, наглядно изображающие два класса.
Этап 5 Очищение ячеек. Начальные данные, вводимые для исследования, всегда различны. Поэтому на пользовательской форме предусмотрена кнопка, выполняющая полную очистку ячеек с ранее полученными результатами.
Заключение
В ходе статьи изучены:
- краткие теоретические сведения о типах методов кластерного анализа, об алгоритмах прямой классификации;
- сведения об оценке функции распределения с помощью нормальной вероятностной бумаги;
- теоретические сведения о статистической аппроксимации законов распределения, гистограмме и полигоне частот, оценке плотности распределения вероятностей «ядерного» типа.
С целью более глубокого изучения задач статистического описания объектов разработаны алгоритмы и программные обеспечения посредством VisualBasicforApplication в среде встроенного пакета анализа данных EXEL.
В ходе выполнения статьи на основе теоретических сведений и разработанных алгоритмов программного обеспечения разработаны и реализованы в среде встроенного пакета анализа данных MicrosoftEXCEL средства автоматизации, которые позволяют быстро и эффективно получить требуемую информацию о классификации выборки упрощенным методом К – ближайших соседей, о правильности выполнения лабораторной работы на тему «Оценка функции распределения с помощью нормальной вероятностной бумаги» из курса «Пакеты статистической обработки данных», а также аппроксимировать неизвестную функцию плотности распределения непараметрическими методами.
Литература
- Айвазян С.А., Бухштабер В.М., Енюков И.С. и др. Прикладная статистика: Классификация и снижение размерности. - М.: Финансы и статистика. -605с.
- Айвазян С.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: основы моделирования и первичная обработка данных. - М.: Финансы и статистика. -472c.
- Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ. -М.: Мир.1982. -405с.
- О формировании эмпирического образа данных/ Осипенко А.Н., Осипенко Н.Б.//-M.: НТИ. Сер. 2. 1990. -С.30-35.
- Пособие для лабораторных занятий по спецкурсу «Обработка экспериментальных данных на ЭВМ» (для специальностей Н.01.01 и Н.08.01)/ Максимей И.В., Осипенко Н.Б., Осипенко А.Н. Гомель: ГГУ, 1998. -54с.
- Мандель И.Д. Кластерный анализ. - М.: Финансы и статистика, 1988. -172с.