В данной статье рассматривается возможность использования нейросетей для построения системы распознавания речи. На основе нейросетей стр оя т ся иерархические многоуровневы е структуры, при этом сохраняется их прозрачность, так как многие нейросетевые алгоритмы осуществляют параллельную обр а бот ку информации, тем самым решая проблемы со скоростью распознавания.
Теоретическое исследование нейросетевых алгоритмов ведется уже давно, и на данный момент они уже широко применяются для решения практических задач. В связи с очевидной конкурентоспособностью этого способа обработки информации по сравнению с существующими на сегодняшний момент традиционными способами особый интерес представляет проблема определения круга задач, для которых было бы эффективным применение нейросетевых алгоритмов. Распознавание образов - это одна из задач, успешно решаемых нейросетями. Одним из приложений теории распознавания образов является распознавание речи. Проблема распознавания речи как одно из составляющих искусственного интеллекта давно привлекала исследователей, и на сегодняшний день хоть и достигнуты определенные успехи, она остается открытой. Объединенная с проблемой синтеза речи, она представляет очень интересное поле для исследований.
Что понимается под распознаванием речи? Это может быть преобразование речи в текст, распознавание и выполнение определенных команд, выделение из речи каких либо характеристик (например, идентификация диктора, определение его эмоционального состояния, пола,возраста, и т.д.) – все это в разных источниках может попасть под это определение. Под распознаванием речи понимается отнесение звуков речи или их последовательности (фонем, букв, слов) к какому-либо классу. Затем этому классу могут быть сопоставлены символы алфавита – получим систему преобразования речи в текст, или определенные действия – получим систему выполнения речевых команд. Вообще этот способ обработки речевой информации может использоваться на первом уровне какой-либо системы с гораздо более сложной структурой. И от эффективности этого классификатора будет зависеть эффективность работы системы в целом.
Какие проблемы возникают при построения системы распознавания речи? Главная особенность речевого сигнала в том, что он очень сильно варьируется по многим параметрам: длительность, темп, высота голоса, искажения, вносимые большой изменчивостью голосового тракта человека, различными эмоциональными состояниями диктора, сильным различием голосов разных людей. Два временных представлени я звука речи даже для одного и того же человека, записанные в один и тот же момент времени, не будут совпадать. Необходимо искать такие параметры речевого сигнала, которые полностью описывали бы его (т.е. позволяли бы отличить один звук речи от другого), но были бы в какой-то мере инвариантны относительно описанных выше вариаций речи. Полученные таким образом параметры должны затем сравниваться с образцами, причем это должно быть не простое сравнение на совпадение, а поиск наибольшего соответствия. Это вынуждает искать нужную форму расстояния в найденном параметрическом пространстве.
Далее, объем информации, которую может хранить система, не безграничен. Каким образом запомнить практически бесконечное число вариаций речевых сигналов? Очевидно, здесь не обойтись без какой-либо формы статистического усреднения.
Ещё одна проблема – это скорость поиска в базе данных. Чем больше её размер, тем медленнее будет производиться поиск – это утверждение верно, но только для обычных последовательных вычислительных машин. А какие же ещё машины смогут решить все вышеперечисленные проблемы? Это нейросети.
Нейросети – это адаптивные системы для обработки и анализа данных, которые представляют собой математическую структуру, имитирующую некоторые аспекты работы человеческого мозга и демонстрирующие такие его возможности, как способность к неформальному обучению, способность к обобщению и кластеризации неклассифицированной информации, способность самостоятельно строить прогнозы на основе уже предъявленных временных рядов. Главным их отличием от других методов, например таких, как экспертные системы, является то, что нейросети в принципе не нуждаются в заранее известной модели, а строят ее сами только на основе предъявляемой информации. Именно поэтому нейронные сети и генетические алгоритмы вошли в практику всюду, где нужно решать задачи прогнозирования, классификации, управления - иными словами, в области человеческой деятельности, где есть плохо алгоритмизуемые задачи, для решения которых необходимы либо постоянная работа группы квалифицированных экспертов, либо адаптивные системы автоматизации, каковыми и являются нейронные сети. Для того чтобы нейронная сеть могла решать эти задачи, ее нео бходимо обучить. Способность к обучению является основным свойством мозга. Для искусственных нейронных сетей под обучением понимается процесс настройки архитектуры сети (структуры связей между нейронами) и весов синаптических связей (влияющих на сигналы коэффициентов) для эффективного решения поставленной задачи. Обычно обучение нейронной сети осуществляется на некоторой выборке. По мере процесса обучения, который происходит по некото рому алгоритму, сеть должна все лучше и лучше (правильнее) реагировать на входные сигналы. Выделяют три парадигмы обучения: с учителем, самообучение (без учителя) и смешанная. В первом способе известны правильные ответы к каждому входному примеру, а веса подстраиваются так, чтобы минимизировать ошибку. Обучение без учителя позволяет распределить образцы по категориям за счет раскрытия внутренней структуры и природы данных. При смешанном обучении комбинируются два вышеизложенных подхода.
Обучить нейронную сеть - значит, сообщить ей, чего мы от нее добиваемся. Этот процесс очень похож на обучение ребенка алфавиту. Показав ребенку изображение буквы "А", мы спрашиваем его: "Какая это буква?" Если ответ неверен, мы сообщаем ребенку тот ответ, который мы хотели бы от него получить: "Это буква А". Ребенок запоминает этот пример вместе с верным ответом, то есть в его памяти происходят некото рые изменения в нужном направлении. Мы будем повторять процесс предъявления букв снова и снова до тех пор, когда все 33 буквы будут твердо запомнены. Такой процесс называют "обучение с учителем".
При обучении нейронной сети мы действуем совершенно аналогично (см. рисунок 1). У нас имеется некоторая база данных, содержащая примеры (набор изображений букв). Предъявляя изображение буквы "А" 81 на вход нейронной сети, мы получаем от нее некоторый ответ, не обязательно верный. Нам известен и верный (желаемый) ответ – в данном случае нам хотелось бы, чтобы на выходе нейронной сети с меткой "А" уровень сигнала был максимален. Обычно в качестве желаемого выхода в задаче классификации берут набор (1, 0, 0, ...), где 1 стоит на выходе с меткой "А", а 0 - на всех остальных выходах. Вычисляя разность между желаемым ответом и реальным ответом сети, мы получаем 33 числа - вектор ошибки. Одну и ту же букву (а также различные изображения одной и той же буквы) мы можем предъявлять нейронной сети много раз. В этом смысле обучение скорее напоминает повторение упражнений в спорте – тренировку. Оказывается, что после многократного предъявления примеров веса нейронной сети стабилизируются, причем нейронная сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что "нейронная сеть выучила все примеры", "нейронная сеть обучена", или "нейронная сеть натренирована". В программных реализациях можно видеть, что в процессе обучения величина ошибки (сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда величина ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную нейронную сеть считают натренированной и готовой к применению на новых данных. Важно отметить, что вся информация, которую нейронная сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения нейронной сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу. Так, например, бессмысленно использовать нейронную сеть для предсказания финансового кризиса, если в обучающей выборке кризисов не представлено. Считается, что для полноценной тренировки нейронной сети требуется хотя бы несколько десятков (а лучше сотен) примеров.
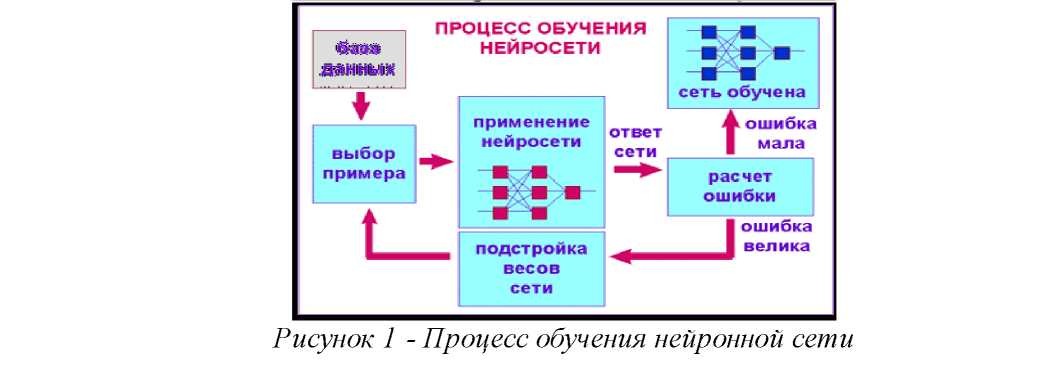
Обучение нейронных сетей – сложный и наукоемкий процесс. Алгоритмы обучения нейронных сетей имеют различные параметры и настройки, для управления которыми требуется понимание их влияния (см. ри
82

После того, как нейронная сеть обучена, мы можем применять ее для решения полезных задач. Важнейшая особенность человеческого мозга состоит в том, что, однажды обучившись определенному процессу, он может верно действовать и в тех ситуациях, в которых он не бывал в процессе обучения. Например, мы можем читать почти любой почерк, даже если видим его первый раз в жизни. Так же и нейронная сеть, грамотным образом обученная, может с большой вероятностью правильно реагировать на новые, не предъявленные ей ранее данные. Например, мы можем нарисовать букву "А" другим почерком, а затем предложить нашей нейронной сети классифицировать новое изображение. Веса обученной нейронной сети хранят достаточно много информации о сходстве и различиях букв, поэтому можно рассчитывать на правильный ответ и для нового варианта изображения.
Для конструирования процесса обучения, прежде всего, необходимо иметь модель внешней среды, в которой функционирует нейронная сеть - знать доступную для сети информацию. Эта модель определяет парадигму обучения. Во-вторых, необходимо понять, как модифицировать весовые параметры сети - какие правила обучения управляют процессом настройки. Алгоритм обучения означает процедуру, в которой используются правила обучения для настройки весов. Наиболее распространенные алгоритмы обучения нейронных сетей:
- Обратное распространение
- Левенберга-Маркара
- Сопряженных градиентов
- Квази-Ньютоновский
- Быстрое распространение
- Дельта-дельта-с-чертой
- Псевдо-обратный
- Обучение Кохонена
- Пометка ближайших классов
- Обучающий векторный квантователь
- Радиальная (под)выборка
- Метод K-средних
- Метод К-ближайших соседей (KNN)
- Установка изотропных отклонений
- Установка явных отклонений
- Вероятностная нейронная сеть
- Обобщенно-регрессионная нейронная сеть
- Генетический алгоритм отбора входных данных
- Пошаговый прямой или обратный отбор входных данных
После того, как определено число слоев и число элементов в каждом из них, нужно найти значения для весов сети, которые бы минимизировали ошибку прогноза, выдаваемого сетью. Именно для этого служат алгоритмы обучения. Этот процесс представляет собой подгонку модели, которая реализуется сетью, к имеющимся обучающим данным. Ошибкадля конкретной конфигурации сети определяется путем прогона через сеть всех имеющихся наблюдений и сравнения реально выдаваемых выходных значений с желаемыми (целевыми) значениями. Предпочтение следует отдавать тем алгоритмам, которые позволяют обучить нейронную сеть за небольшое число шагов и требуют мало дополнительных переменных. Это связано с тем, что обучение сетей производится на компьютерах с ограниченным объемом оперативной памяти и небольшой производительностью. Как правило, для обучения используются персональные компьютеры.
Стохастические алгоритмы требуют очень большого числа шагов обучения. Это делает невозможным их практическое использование для обучения нейронных сетей больших размерностей. Экспоненциальный рост сложности перебора с ростом размерности задачи в алгоритмах глобальной оптимизации также делает невозможным их использование для обучения нейронных сетей больших размерностей. Метод сопряженных градиентов очень чувствителен к точности вычислений, особенно при решении задач оптимизации большой размерности. Методы, учитывающие направление антиградиента на нескольких шагах алгоритма, и методы, включающие в себя вычисление матрицы Гессе, требуют дополнительных переменных.
Все используемые на данный момент алгоритмы обучения нейронных сетей базируются на оценочной функции, которой оценивается качество работы всей сети в целом. При этом имеется некоторый алгоритм, который в зависимости от полученного значения этой оценки каким-то образом подстраивает изменяемые параметры системы. Обычно эти алгоритмы характеризуются сравнительной простотой, однако не позволяют за приемлемое время получить хорошую систему управления или модель для достаточно сложных объектов. Именно здесь человек пока еще намного опережает в скорости настройки любую автоматику.
Классификация - это одна из «любимых» для нейросетей задач. Причем нейросеть может выполнять клас сификацию даже при обучении без учителя (правда, при этом образующиеся классы не имеют смысла, но ничто не мешает в дальнейшем ассоциировать их с другими классами, представляющими другой тип информации - фактически наделить их смыслом). Любой речевой сигнал можно представить как вектор в каком- либо параметрическом пространстве, затем этот вектор может быть запомнен в нейросети. Одна из моделей нейросети, обучающаяся без учителя - это самоорганизующаяся карта признаков Кохонена. В ней для множества входных сигналов формируются нейронные ансамбли, представляющие эти сигналы. Этот алгоритм обладает способностью к статистическому усреднению, т.е. решается проблема с вариативностью речи. Как и многие другие нейросетевые алгоритмы, он осуществляет параллельную обработку информации, т.е. одновременно работают все нейроны. Тем самым решается проблема со скоростью распознавания - обычно время работы нейросети составляет несколько итераций.
Далее, на основе нейросетей легко строятся иерархические многоуровневые структуры, при этом сохраняется их прозрачность (возможность их раздельного анализа). Так как фактически речь является составной, т.е. разбивается на фразы, слова, буквы, звуки, то и систему распознавания речи логично строить иерархическую.
Наконец, ещё одним важным свойством нейросетей является гибкость архитектуры. Автоматическое создание алгоритмов – это мечта уже нескольких десятилетий. Но создание алгоритмов на языках программирования пока под силу только человеку. Конечно, созданы специальные языки, позволяющие выполнять автоматическую генерацию алгоритмов, но и они не намного упрощают эту задачу. А в нейросетях генерация нового алгоритма достигается простым изменением её архитектуры. При этом возможно получить совершенно новое решение задачи. Введя корректное правило отбора, определяющее, лучше или хуже новая нейросеть решает задачу, и правила модификации нейросети, можно, в конце концов, получить нейросеть, которая решит задачу верно. Все нейросетевые модели, объединенные такой парадигмой, образуют множество генетических алгоритмов. При этом очень четко прослеживается связь генетических алгоритмов и эволюционной теории (отсюда и характерные термины: популяция, гены, родители-потомки, скрещивание, мутация).
Таким образом, с уществует возможность создания таких нейросетей, которые не были изучены исследователями или не поддаются аналитическому из учению, но тем не менее успешно решают задачу.
ЛИТЕРАТУРА
- Ф. Уоссермен. Нейрокомпьютерная техника: Теория и практика. Перевод на русский язык Ю. А. Зуев, В. А. Точенов, 1992. – 392 с.
- Винцюк Т.К. Анализ, распознавание и интерпретация речевых сигналов. -Киев: Наук. думка, 1987. – 262 с.
- А.А. Ежов, С.А. Шумский НЕЙРОКОМПЬЮТИНГ и его приложения в экономике. - МИФИ, 1998 – 451 с.