На абстрактном уровне в любой адаптивной гипермедиа-системе функционально можно выделить следующие три основные взаимодействующие компоненты: модель предметной области (domain model), которая описывает, как структурировано информационное содержимое приложение (или гипердокумента); модель пользователя (user model), представляющая пользовательские предпочтения, знания, цели, историю навигации и другие относящиеся к пользователю характеристики; модель обучения (teaching model), называемая также моделью адаптации (adaptation model), позволяющая осуществить необходимые адаптации системы, например, с помощью так называемых педагогических правил (pedagogical rules) или правил адаптации (adaptation rules).
Помимо указанных трех моделей адаптивная гипермедиа система может содержать так называемый механизм адаптации (adaptive engine). Это – реальный программный продукт, являющийся частью системы, который используется ею для конструирования и адаптации содержимого и ссылок. Механизм поддерживает некоторую библиотеку функций для конструирования информационных страниц из фрагментов, основанных на элементах из моделей предметной области, пользователя и адаптации. Язык (обычно довольно простой) применяется с целью выбора «конструкто ра» для использования. Некоторые механизмы адаптации могут поддерживать способ определения новых конструкторов или расширения существующих [1]. Однако, достаточно мощный механизм должен поддерживать достаточно стандартную функциональность для облегчения потребностей авторов явно специфицировать новые конструкторы в большинстве приложений. Механизм адаптации также изменит пользовательскую модель, отслеживая поведение пользователя и, таким образом, принимая во внимание, как изменяются его знания.
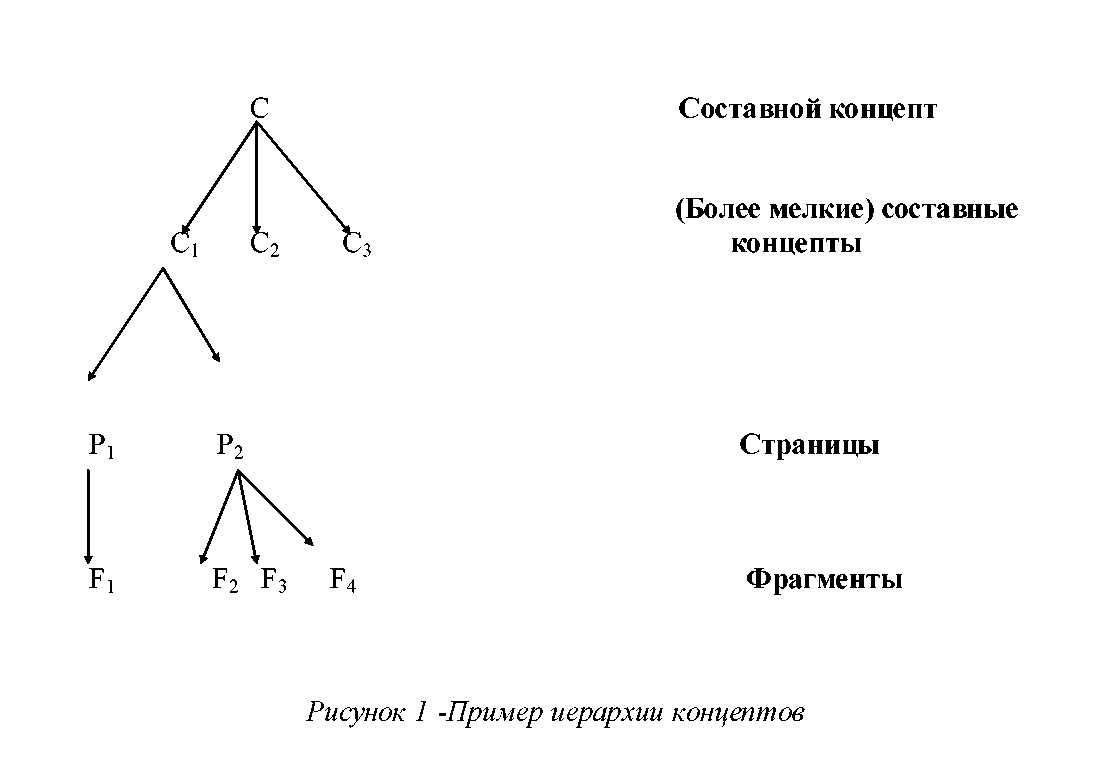
Модель предметной области дает описание предметной области на концептуальном уровне и представляет собой совокупность объектов (концептов и межконцептных отношений), каждый из которых имеет уникальное имя (Рис.1).
Концепты – это абстрактные объекты, используемые для представления элементов информации предметной области. Существуют концепты нижнего уровня (атомарные концепты или фрагменты), каждый из которых с оответствует одному фрагменту инфо рмации, и концепты высшего уровня (или с оставные концепты), состоящие из множества других концептов. Атомарные концепты являются первичными в модели и могут не подвергаться адаптации. Их атрибутные и анкерные значения принадлежат «внутрикомпонетному уровню» и таким образом являются зависимыми от реализации и не описываемыми в модели. Составные концепты имеют два специальных атрибута: последовательность детей (концептов) и функция конструктора (для обозначения, как дети соединяются). Если все дети некоторого концепта атомарны, то такой концепт называют страницей.
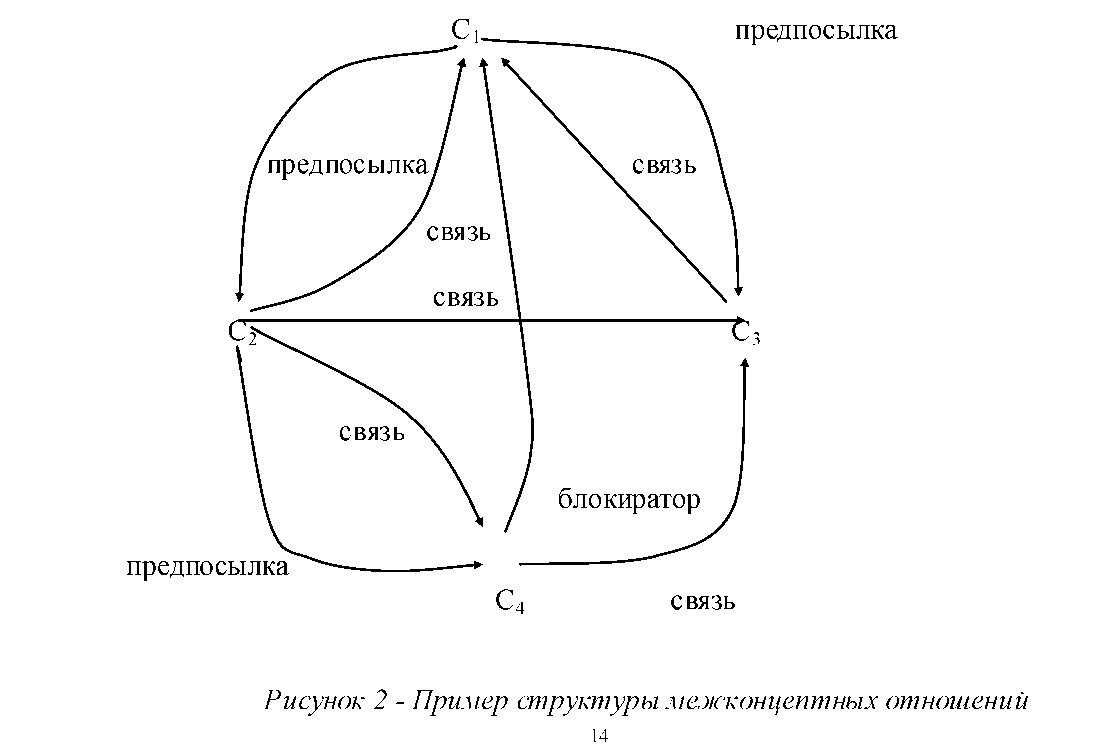
Межконцептные отношения представляют различные отношения между двумя или более концептами. Например, часто используются следующие типы бинарных отношений между парами концептов: тип часть (part- of)- это композиционное отношение, указывающее на то, что первый концепт является частью второго; тип связь (link) представляет существование связи первого концепта со вторым (например, в виде гиперссылки); тип предпосылка (prerequisite) означает, что первый концепт должен быть предварительно изучен до изучения второго
13 концепта; тип блокиратор (inhibitor) говорят о том, что первый концепт не должен изучаться до тех пор, пока не будет изучен второй (Рис.2).
Межконцептные отношения могут иметь атрибуты. Например, приписывая некоторое вещественное число из интервала [0,1] тому или другому бинарному отношению можно указать: для отношения типа часть – какую часть второго концепта представляет первый концепт; для отношения типа предпосылки – как много знаний о первом концепте должно быть у пользователя, чтобы информация о втором концепте становилась желаемой; для отношения типа блокировки – какую границу знаний о первом концепте должны превысить знания пользователя, чтобы стало нежелательным получение знания о втором концепте.
Можно выделить три типа моделей предметной области, различающихся по уровню сложности структуры [2]. Самую простую структуру имеет модель первого уровня, являющаяся независимым множеством концептов (отсутствуют межконцептные отношения). Модель второго уровня (сетевая модель предметной области) предполагает наличие связей между концептами и представляет собой семантическую сеть, состоящую из концептов и межконцептных отношений. Может существовать несколько типов концептов и межконцептных отношений. Модель третьего уровня (фреймовая модель предметной области) предполагает наличие у концептов внутренней структуры в виде множества атрибутов, при этом концепты различных типов могут иметь различные множества атрибутов.
Одной из самых важных функций модели предметной области является обеспечение структуры для представления знаний пользователя системой.
Адаптивные гипермедиа- системы можно подразделить на три основные группы в зависимости от метода организации связи между моделью предметной области (концептами) и гиперпространством системы (гипермедиа- страницами). Самый простой метод – это индексация страниц концептами, относящимся к содержимому этих страниц. Второй метод, похожий на предыдущий, это - индексация фрагментов: содержимое страницы разбивается на множество
фрагментов, каждый из которых отдельно индексируется множеством концептов, относящихся к содержимому данного фрагмента. Третий метод (прямая связь) отличается от предыдущих методов тем, что для страниц не поддерживается индексы; гиперпространство адаптивной гипермедиасистемы строится непосредственно исходя из структуры модели предметной области. Таким образом, каждый концепт модели представлен гипермедиа- страницей или гипердокументом, а отношения между концептами соответствуют гиперссылками между страницами. Страница или документ, представляющий концепт, могут быть как статистическими, так и динамическими: т.е. генерироваться на лету, исходя из внутренней структуры концепта.
Модель пользователя адаптивной гипермедиа- системы предполагает явное представление знаний, целей, интересов, истории навигации и других характеристик пользователя и служит для адаптации к нему различных аспектов адаптивной гипермедиа- системы. Модель пользователя состоит из именованных элементов, для которых хранится набор пар вида атрибут – значение (компонентов модели пользователя). На концептуальном уровне можно представлять ее в виде табличной структуры, в которой для каждого элемента хранятся значения атрибутов. Большинство элементов в модели пользователя представляют концепты модели предметной области. Некоторые другие элементы могут кодировать различные аспекты пользователя, такие как цели, предпо чтения, интересы или стереотипную класс ификацию (типа новичок, эксперт) и т.д.
Можно классифицировать модели пользователей согласно следующим основным свойствам: способ получения информации (явный или неявный), степень специализации модели (общие или индивидуальные модели), модифицируемость модели (статистические или динамические модели), временная протяженность (краткосрочные или долгосрочные модели), метод использования модели (дескриптивные или прескриптивные модели).
Различаются два основных подхода к моделированию пользо вателя: моделирование перекрытий и моделирование стереотипного пользователя.
Оверлейное моделирование или моделирование перекрытий (overlay modeling) [2] чаще всего используется в интеллектуальных системах обучения для моделирования знаний, при этом знания пользователя описываются как подмножество знаний эксперта в данной области, отсюда сам термин «перекрытие» («оверлей») (Рис.3). Недостаток знаний обучающегося выводится посредством сравнения их со знаниями эксперта. Для каждого концепта модели предметной области в модели знаний пользователя вычисляется и сохраняется некоторое значение (или несколько значений), оценивающее уровень знания этого концепта (оверлейная модель). Оверлейная модель знаний (overlay model) может быть представлена как множество пар «концепт- значения атрибутов».
Таким образом, в рамках оверлейной модели предполагается, что знание пользователя составляет некоторое подмножество знания эксперта, и цель обучения состоит в расширении этого подмножества. Модель также предполагает, что пользователь не будет изучать того, чего не знает эксперт. В частности, не принимаются во внимание неправильные представления и заблуждения, изначально имеющиеся у пользователя, или приобретенные им в процессе обучения. Второй недостаток оверлейной модели заключается в том, что нет механизма для разграничения знаний, которые пользователь еще не приобрел, и знаний, которые еще не были ему представлены, что имеет смысл для стратегии обучения.
Дифференциальная модель (Differential model) является расширением оверлейной модели. В ней знания эксперта разделены на те, которые уже были представлены пользователю, и те, которыми пользователь еще не обязан обладать, а простая оверлейная модель применяется лишь к
16 знаниям, уже представленным пользователю. Аналогично оверлейной, дифференциальная модель не принимает во внимание неправильные представления и ошибки пользователя.

Пертурбационная модель (Perturbation model) принимает во внимание те знания, которыми может обладать пользователь вне знаний эксперта. Пертурбационная модель расширяет модель эксперта добавлением библиотеки ошибок (bug library). Процесс ее создания может быть перечисляющим или порождающим. Перечисляющий процесс составляет список всех возможных неправильных представлений с помощью анализа предметной области и ошибок, которые допускает пользователь. Порождающий метод пытается генерировать ошибки исходя из лежащей в основе познавательной теории. Оверлейная модель может быть применена поверх комбинированной модели эксперта и библиотеки ошибок. Как и для простой оверлейной модели, цель обучения - увеличить подмножество знания эксперта при исключении неправильных представлений.
Стереотипное моделирование (stereotype modeling) - один из первых методов в области моделирования, классифицирующий пользователей по стереотипам. Предполагается, что пользователи, относящиеся к одному классу, имеют одни и те же характеристики. При использовании стереотипной модели иногда полезно различать два типа стереотипного моделирования: фиксированно е моделирование и моделирование по умолчанию.
Стереотип в общем случае состоит из следующих частей: множества инициирующих условий (триггеров), являющихся логическими выражениями, активирующими стереотип; множества условий отвода (ретракций), ответственных за деактивацию активного стереотипа; множества предположений (выводов) стереотипа, служащих предположениями по умолчанию при связывании пользователя со стереотипом. Выделяют четыре модели согласно типу организации связи между стереотипами (Рис.4).

Рисунок 4 - Виды моделей знаний при стереотипном моделировании
Многоуровневая (или луковая) модель (onion model)- это иерархическая модель, где содержимое стереотипов линейно упорядочено по отношению быть подмножеством. Летисная (или салатная) модель (lettuce model) характеризуется наличием стереотипа – ядра, содержимое которого является подмножеством содержимого всех других стереотипов, в остальном независимых друг от друга. Многоядерная летисная (или многоядерная салатная) модель (multikernel lettuce model) является обобщением летисной модели, допускающей существование нескольких ядер, являющихся пересечениями некоторых стереотипов. Ориентированный ациклический граф (DAG1) является обобщением многоядерной модели, допускающей существование общих частей у двух или более ядер, также представляющихся ядрами, и т.д.
Модель адаптации описывает, как должна происходить адаптация в зависимости от предметной области. Она состоит из правил адаптации, которые формируют связь между моделью предметной области и моделью пользователя и определяют представление генерируемой информации и обновление пользовательской модели.
Обычно правило содержит две основные части: условие, при котором происходит срабатывание данного правила, и трансформация – описание того действия, которое задается данным правилом. Условие может предполагать возникновение некоторого внешнего события (такие правила называются ЕСА- правилами, в отличие от СА- правил, в которых условие – это просто логическое выражение), например, обращения к странице, а также истинность некоторого логического выражения, построенного над значениями атрибутов из моделей пользователя и предметной области и проверяемого в те моменты, когда событие возникает. Действие может состоять в модификации значений атрибутов в модели пользователя или в присваивании объекту спецификации представления. Также, в правиле может быть «фаза» выполнения, указывающая на момент времени, в который должно применяться правило: до или в течение генерации (фаза “pre”) и после генерации страницы (фаза “post”). Также в правиле может быть определено, может оно инициировать запуск других правил или нет.
В качестве примера можно привести два простых правила, написанных используя произвольно выбранный синтаксис.
Например, следующее правило определяет, что при обращении к странице для соответствующего концепта в модели пользователя устанавливается атрибут «чтение» равным истине в фазе “post”.
<access (C)=>C .read:=true ;post; true>
Правило также утверждает, что оно запустит другие правила, которые имеют атрибут «чтения» (C .read:=true) в своей левой части.
Другой пример. Следующее правило выражает, что когда пользователь обращается к странице, определяющий концепт, «готовый для чтения», то значение знания для этого концепта становится «изученным» в фазе “pre”:
< access (C) &C.ready-to-read=true)=>
C. knowledge-value: =learned; pre; true>
Все правила адаптации подразделяются на родовые или обобщенные правила (generic rules) и специфические или конкретные правила (specific rules). В отличие от обобщенных правил, которые применимы ко всем концептам и всем межконцептным отношениям некоторого заданного типа и используют связанные переменные для представления в них концептов и межконцептных отношений, специфические правила описывают преобразования для конкретных концептов, множеств концептов и межконцептных отношений и не используют переменных. Специфические правила имеют приоритет над обобщенными правилами и, таким образом, они используются для определения исключений в общих правилах.
Предложенная нами архитектура гипермедиа системы может быть использована при разработке адаптивной системы дистанционного обучения АСДО.
Литература
- Зайцева Л.В. Методы и модели адаптации к учащимся в системах компьютерного обучения //Educational Technology & Society. — 2003. -Vol 6, N 4. - С. 143.
- Баймухамедов М.Ф. Интеллектуализация компьютерного обучения в системе образования Республики Казахстан. // . Монография. Изд-во КГУ им. А.Байтурсынова, Костанай, 1995. – 345 с.