Постоянный рост информации, низкая интероперабельность систем предъявляют более жесткие требования к информационным технологиям. На сегодняшний день большая часть информации в интернете представлена в непригодном для машинной обработки виде. Даже информация, полученная из структурированных баз данных, не определена достаточно для того, чтобы иметь возможность понимать и использовать ее машинами. Для решения этих проблем было предложено вести обработку информации на семантическом уровне. Semantic web является видением будущего Web. В этом видении машина выдает более точные значения, которые позволяют выполнять интеграцию, обработку и понимание информации в интернете.
Важнейшим компонентом Semantic web, позволяющим представлять в явно выраженном виде знания о предметной области, являются онтологии. Более того, онтологии определяют отношения между понятиями, что позволяет создавать программы, учитывающие семантику этих отношений [5].
Консорциум всемирной паутины (W3C) определил некоторые стандарты и языки, такие как RDF (Resource Description Framework), в качестве представления модели данных, RDF Schema, в качестве языка описания лексики и OWL (Web Ontology Language) для определения смысла терминов и их отношений, используемых в словарях. В Semantic web знания описываются триплетом – субъект, предикат, объект. Субъект и предикат являются сущностями, обладающими URI ( Uniform Resource Identifier). Объект может быть как литералом, так и сущностью. Для получения информации из RDF графов используется язык запросов SPARQL, который предоставляет возможность получения информации из различных форм, таких как URI, узлы, простые и типизированные литералы [3] .
База знаний в сочетании с системой логического вывода могут находить новые факты из уже имеющихся. Применение правил к фактам могут порождать новые знания. Для извлечения знаний применяются интеллектуальные агенты, которые используют готовые факты либо порождают новые с помощью логического вывода из правил.
Задачей любой информационной системы, основанной на знаниях, является предоставление требуемых результатов поиска, будь то простой или сложный запрос. Semantic web использует достаточно средств для ответа на конкретный запрос, а так же обладает необходимой гибкостью, позволяющей менять структуру данных без ущерба для них, позволит приложениям автоматически обрабатывать, интегрировать, формировать информацию из различных источников, обеспечивать поиск по содержимому, а не только по ключевым словам, работать с другими приложениями и сервисами, которые позволят агентам манипулировать соответствующей информацией. Эффективность таких программных агентов будет расти экспоненциально по мере увеличения количества доступного машинно-воспринимаемого контента и автоматизированных сервисов [4].
Продукционная модель знаний
Увеличение глубины вложенности правил, рост сложности логического вывода являются основным препятствием применения продукционной модели в практических задачах.
Одним из решений данной проблемы является применение метода сопоставления списка вторичных фактов, позволяющие уменьшить сложность извлечения знаний.
Ускорить выполнение правил можно при условии запоминания результатов применения правил к базе знаний в виде вторичных фактов (прецедентов). Данный метод позволяет избежать необходимости углубления по дереву поиска и сократить время извлечения нового факта [1].
Постановка задачи
Пусть база первичных фактов составляет множество триплетов (s,p,o), где s – субъект, p- предикат, определяющий отношение «отец/мать» , o- объект. Субъекты и объекты идентифицируются случайными числами в диапазоне (0-1000), (1000-2000), (2000-3000),(3000-4000),(4000-5000), представляющие четыре поколения[2].
База прецедентов представляет собой работу правила, представляющее отношение «прапрабабушка/прапрадедушка» и «брат/сестра». Ускорение извлечение факта, осуществляется за счет запоминания результатов применения правила в предыдущих обращениях в виде вторичных фактов. Первичными фактами являются факты, которые не являются результатом работы правила. Выполняется сравнение времени, затраченное на извлечение нового факта, используя базу прецедентов и базу первичных фактов.
Применение метода, использующего базу прецедентов, позволяет устранить необходимость углубления по дереву поиска, избежав необходимости использования повторяющихся фрагментов, путем обращения к прецедентам.
Оценка быстродействия метода
Предполагаемый метод был реализован с помощью фреймворка Jena. Тестирование проводилось на базе, определяющей родственные отношения. Первичная база фактов была сгенерирована целыми числами, содержащими отношение «отец/мать» (parentOf).
Прецеденты «прапрабабушка/прапрадедушка» (grandgrandparentOf) и «брат/сестра»
(siblingOf) были найдены и сохранены в базе прецедентов на основе правил:
@prefix rel: <http://relationship/> [sibling:
(?a rel:parentOf ?b)
(?a rel:parentOf ?c), notEqual(?b,?c)
->
(?b rel:siblingOf ?c)
]
[grandgrandparent: (?a rel:grandgrandparentOf ?d)
<-
(?a rel:parentOf ?b) (?b rel:parentOf ?c) (?c rel:parentOf ?d)
]
Правило, которое использовалось для измерения времени вывода новых фактов на основе прецедентов, описывает отношение «троюродный брат» (thirdcousinOf):
@prefix fam: <http://family/> [thirdcousin: (?c3 rel:thirdcousinOf ?d3)
<-
(?a3 rel:siblingOf ?b3)
(?a3 rel:grandgrandparentOf ?c3) (?b3 rel:grandgrandparentOf ?d3)
]
Для сравнения времени вывода новых фактов на основе первичных фактов использовалось правило, так же описывающее отношение «троюродный брат» (thirdcousinOf):
@prefix rel: <http://relationship/>
[sibling: (?b rel:siblingOf ?c)
<-
(?a rel:parentOf ?b)
(?a rel:parentOf ?c), notEqual(?b,?c)
]
[grandparent: (?a1 rel:grandparentOf ?c1)
<-
(?a1 rel:parentOf ?b1) (?b1 rel:parentOf ?c1)
]
[grandgrandparent: (?a2 rel:grandgrandparentOf ?c2)
<-
(?b2 rel:parentOf ?c2)
(?a2 rel:grandparentOf ?b2)
]
[thirdcousin: (?c3 rel:thirdcousinOf ?d3)
<-
(?a3 rel:siblingOf ?b3)
(?a3 rel:grandgrandparentOf ?c3) (?b3 rel:grandgrandparentOf ?d3)
]
В табл. 1 представлены результаты исследования времени создания, извлечения прецедентов в зависимости от числа фактов, а также время извлечения фактов, определяющие отношение
«thirdcousinOf» с использованием базы первичных фактов и прецедентов.
Таблица 1. Результаты исследования
|
Количество первичных фактов |
Время создания базы первичных фактов |
Время создания одного прецедента |
Время извлечения одного факта на основе базы прецедентов |
Суммарное время создания прецедента и извлечения факта |
Время извлечения одного факта на основе базы первичных фактов |
|
2000 |
1 |
0,0015 |
0,0005 |
0,002 |
0,006 |
|
4000 |
2 |
0,0019 |
0,0006 |
0,0025 |
0,0295 |
|
8000 |
2 |
0,0031 |
0,0008 |
0,0039 |
0,0874 |
|
10000 |
2 |
0,0034 |
0,0017 |
0,0051 |
1,0483 |
|
20000 |
2 |
0,0099 |
0,0245 |
0,0344 |
2,0037 |
|
30000 |
2 |
0,0162 |
0,0384 |
0,0546 |
2,9472 |
|
40000 |
2 |
0,0407 |
0,1347 |
0,1754 |
3,7345 |
|
50000 |
2 |
0,0813 |
0,6477 |
0,729 |
5,6782 |
|
60000 |
3 |
0,1974 |
1,4623 |
1,6597 |
8,864 |
|
70000 |
3 |
1,4278 |
2,3745 |
3,8023 |
10,1422 |
|
80000 |
3 |
2,4271 |
3,9758 |
6,4029 |
15,1256 |
|
90000 |
3 |
2,7854 |
5,4768 |
8,2622 |
19,4578 |
|
100000 |
3 |
3,5647 |
6,2471 |
9,8145 |
23,7812 |
|
100 |
|||||
|
10 |
|||||
|
1 |
|||||
|
0 |
20000 |
40000 60000 80000 |
100000 |
120000 |
|
|
0,1 |
|||||
|
0,01 |
|||||
|
0,001 |
|||||
|
Количество фактов |
|||||
|
Время извлечения одного факта на основе базы первичных фактов Суммарное время создания прецедента и извлечения факта. |
|||||

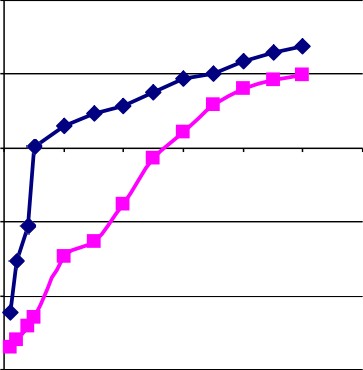
 Рис.1. Время обработки фактов на основе прецедентов и базы первичных фактов
Рис.1. Время обработки фактов на основе прецедентов и базы первичных фактов
На рис. 1 представлены графики времени обработки фактов на основе прецедентов и базы первичных фактов. Показано, что время извлечения фактов на основе прецедентов существенно меньше времени обработки правил.
 Время, с
Время, с
Представленная модель может быть использована в экспертных системах, логических агентах и в технологиях Semantic web. Проведенное исследование позволяет сделать вывод, что данный метод позволяет ускорить логический вывод в продукционной модели знаний. Увеличения времени извлечения факта по мере роста базы прецедентов является более приемлемым, нежели время, затраченное на работу правила с применением базы первичных фактов.
ЛИТЕРАТУРА
- Бессмертный И.А. Управление интеллектуальными навыками в базах знаний // Теория и системы управления. -Санкт-Петербург, 2011
- Бессмертный И.А. Теоретико-множественный подход к логическому выводу в базах знаний // Научно-технический вестник СПбГУИТМО. - Санкт-Петербург: СПбГУИТМО, 2010. - Т. 66, вып. 2. - С. 43- 48. - 128 с. - ISSN 1819-222Х.
- Hammad H.R. Semantic Web Solutions//final thesis – IT University of Copenhagen, 2007, - С. 7-12- 100с.
- Rezara J.M. A System for Management of Semantic Data (OntologyComponents) in Semantic Web//Royal Institute of Technology -Sweden, 2007 –C. 5-27. – 167 с.
- Рассел, С., Норвиг, П. Искусственный интеллект: Современный подход. 2-е изд. // пер. с англ. – М.: Изд. дом «Вильямс», 2006.