В данной статье рассматривается парадигма программирования MapReduce, изначально предназначавшаяся для абстрагированиясложностей распараллеливания, которая идеально подходит для облачных вычислений, особенно при работе с большими объемами данных.
Облачные вычисления прекрасно дополняют абстракцию MapReduce, позволяя не задумываться о том, где именно осуществляются операции над конкретными числами.
В современном мире информационных технологий с каждым днем растет необходимость обработки больших объемов данных. В связи с этим появляется необходимость разработки концепции обработки, передачи и хранения больших данных. Современной концепцией или парадигмой обработки большого объема данных является концепция Big Data. В настоящее время в области информационных технологий введутся разработки разных типов технологий Big Data.
Одной из наиболее используемых в данное время технологий является MapReduce. Основная идея MapReduce заключается в том, что она используется, как простая парадигма написания кода, который пригоден для массового распараллеливания.
Способность MapReduce отделить семантику оперативного распараллеливания от разработчика делает его совместимым с облачными вычислениями. Используя облако, разработчик может написать сценарий, который загружает любое количество машин и выполняет операции MapReduce.
Сочетание облачных вычислений и MapReduce идеально приспособлено для работы с большими объемами данных. На самом деле MapReduce - это не только программная модель, используя которую можно решать задачи сортировки и группировки данных.
Это - целая архитектура, обеспечивающая:
- автоматическое распараллеливание данных из огромного массива по множеству узлов обработки, выполняющих процедуры Map/Reduce;
- эффективную балансировку загрузки этих вычислительных узлов, не дающую им простаивать или быть перегруженными сверх меры;
- технологию отказоустойчивой работы, предусматривающую тот факт, что при выполнении общего задания часть узлов обработки может выйти из строя или по какой-либо другой причине перестать обрабатывать данные.
Таким образом, MapReduce, с одной стороны, предоставляет пользователю процедуры обработки его данных, а с другой - делает для него прозрачным процесс распараллеливания обработки на кластере.
При проектировании MapReduce была идея разместить модули, реализующие процедуры map и reduce, на тех самых чанк-серверах - основе файловой системы GFS. Такой подход приближает хранящиеся в GPS модули к функциям их обработки. Экономия сетевого трафика в целом.
Технология MapReduce построена по принципу «главный – подчиненные». Главный в MapReduce – процедура Master – управляет множеством разбросанных по чанк-серверам «работников», часть из которых отвечает за функцию map, а остальные, соответственно, за reduce. На вход MapReduce поступает требующий обработки массив, «разрезанный» на M частей размером от 16 до 64 мегабайт. Получив адреса M частей массива, Master MapReduce формирует частные задания для M функций мэпперов и раздает каждой из них адрес чанка, который надлежит подвергнуть процедуре map. Поскольку мэпперы работают параллельно и независимо друг от друга, требуется в M раз меньше времени, чем при линейной обработке.
В результате появляется новый, разделённый на части массив промежуточных данных, содержащих неупорядоченные списки пар ключ – значение. В идеале количество частей этого промежуточного массива должно быть равно R, то есть совпадать с количеством «работников», отвечающих за операцию reduce. Однако на практике массив пар, содержащих один и тот же ключ, может быть значительно больше. Чтобы сократить его размер, MapReduce использует процедуру предварительного агрегирования данных, присваивая таким популярным парам новое промежуточное значение. Эта процедура именуется combine и по своей сути очень похожа на reduce. Combine можно использовать лишь в тех случаях, когда функция, которую используют на стадии reduce для объединения данных, обладает свойствами коммутативности и ассоциативности.
Агрегированный до требуемого размера массив промежуточных данных может поступать на R «работников», выполняющих reduce. Можно отметить, что reduce в простейшем виде работает со всеми значениями одного ключа. Это значит, что на каждого «работника» желательно подать пары с одинаковым ключом. Проблема заключается в том, что они разбросаны по разным частям списка, сформированного мэпперами рис.1.
Последним этапом перед выполнением процедуры reduce является процедура распределения (partitioning) рис.2, в результате которой пары с одинаковым ключом попадают на одних и тех же «работников». Процесс требует времени и значительного сетевого трафика, но всё это компенсируется скоростью работы на следующем этапе.
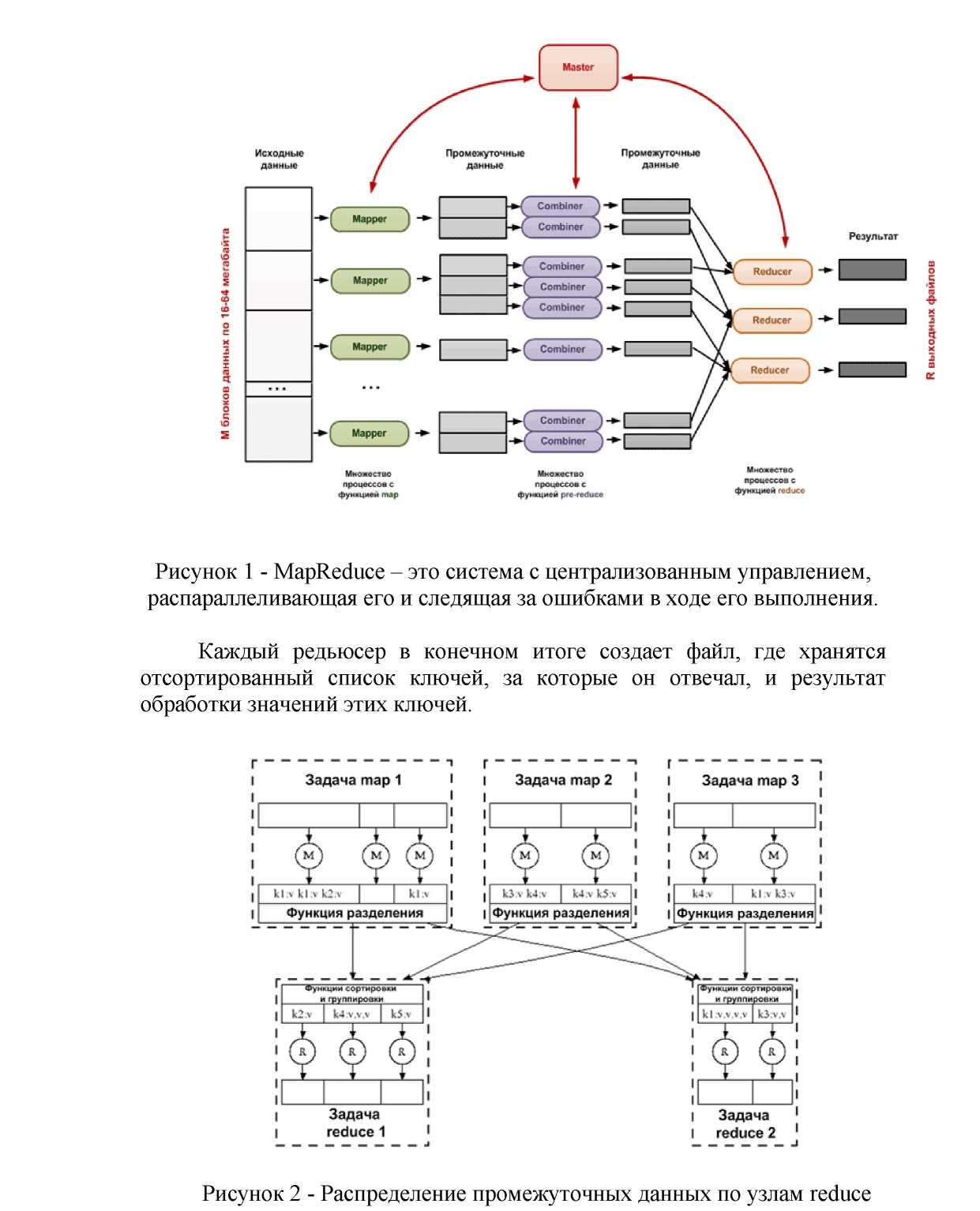
R «работников» создают R результирующих файлов, о чём и докладывают мастеру MapReduce. Получив подтверждение от всех «работников», он считает задание выполненным и передает адреса результирующих файлов клиентскому приложению.
Заключение
Можно отметить, что концепция облачных вычислений охватывает много вариантов применения, включая простое выполнение последовательного сценария на виртуальной машине в центре обработки данных. В данной статье для решения реальной проблемы обработки больших объемов данных использовались MapReduce и облачные вычисления.
В целом реализации MapReduce, основанные на облачных вычислениях на сегодняшний день применяются успешно.
ЛИТЕРАТУРА
- Jimmy Lin and Chris Dyer Data-Intensive Text Processing with MapReduce - Morgan & Claypool Publishers, 2010 - 178с.
- Василий Леонов Google Docs, Windows Live и другие облачные технологии. Перм. гос. техн. ун-т. - Пермь, - 2009. - С.304.